
LLM 에이전트 평가 리더보드
이 내용은 모델 평가에 사용되는 점수 체계, 집계 방식, 비교 분석 및 운영 지표에 대한 정의를 기술합니다.
1. 점수의 기본 정의
각 테스트 케이스 i에 대해 정량적 평가와 정성적 평가를 수행한 후, 더 높은 점수를 최종 점수로 채택합니다.
- 정량 점수 (qi): 기대하는 정답 문자열(Expected Output)이 모델의 응답(Response)에 포함되었는지 여부를 기계적으로 판단합니다. (0 또는 1)
- 정성 점수 (li): LLM Judge가 평가한 점수로, 0과 1 사이의 연속적인 값을 가집니다.
- 대표 점수 (mi): 해당 케이스에서 모델이 획득한 최종 점수로, 정량 점수와 정성 점수 중 최댓값을 사용합니다.
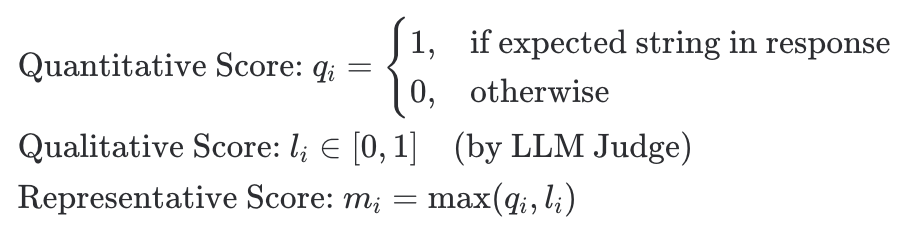
2. 모델별 종합 성능 지표
특정 모델 M이 수행한 전체 케이스 집합 IM (총 개수 NM=∣IM∣)에 대한 통계입니다.
2.1 평균 및 분포
모델의 전반적인 성능 수준을 나타냅니다. 정량/정성 평균과 최종 대표 점수의 평균, 그리고 점수 분포(중앙값, 분위수)를 확인합니다.
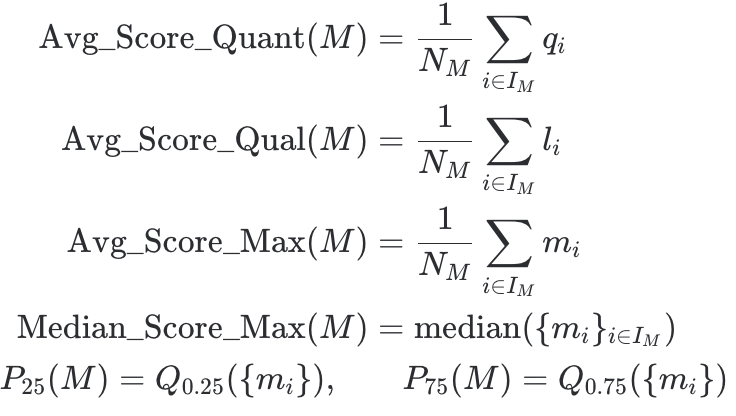
2.2 성공률 및 에러율
- 성공률: 특정 임계값( τ τ ) 이상을 기록한 케이스의 비율입니다. (예: τ = 1.0 τ=1.0 은 완벽한 정답률)
- 에러율: 시스템 오류, API 오류 등 정상적인 답변이 생성되지 않은 케이스의 비율입니다.
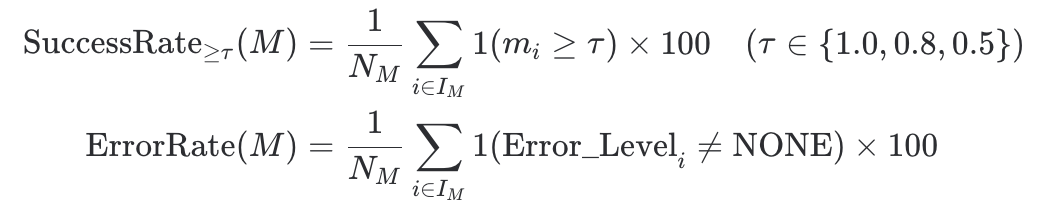
2.3 기준별 평균
특정 평가 기준 c (예: 정확도, 도구 사용 능력, 효율성)에 해당하는 케이스들만 필터링하여 평균 점수를 산출합니다.
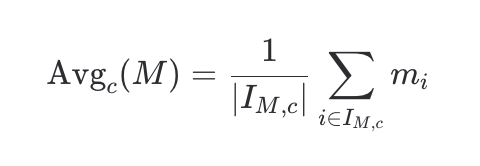
3. 운영 효율성 및 도구 품질
모델의 응답 속도, 추론 비용, 도구(Tool) 호출의 정확성을 평가하는 운영 지표입니다.
3.1 리소스 소모
평균 소요 시간(ms), 추론 단계 수(Steps), 재시도 횟수(Retries)를 측정합니다.
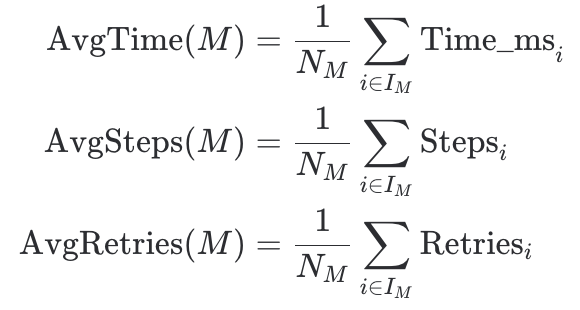
3.2 도구 사용 품질
모델이 외부 도구를 호출할 때의 정확도를 평가합니다.
- LCS F1: 호출 구문의 유사도
- Arg Accuracy: 인자(Argument) 값의 정확도
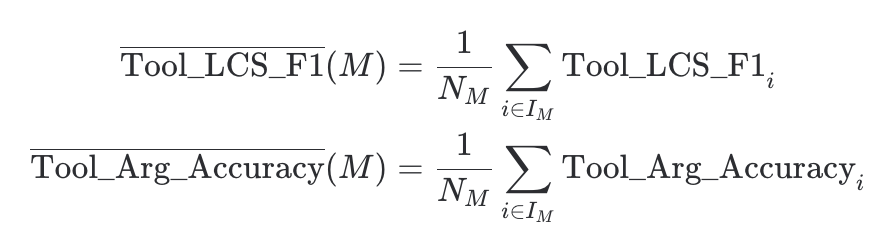
어시웍스 평가 및 결과 URL : https://docs.google.com/spreadsheets/d/1Oa7RTHiXsFNQxKV-s2roDc3J89od1srpZi--RYT-cr0/edit?usp=sharing