
제 5차년도 USG AI·데이터 제조혁신 경진대회의 연습문제 입니다.
초급과 중급의 본 경진대회에 앞서 연습문제를 통해 차근차근 문제를 풀어보세요!
1. 문제 개요 🔩
 |
- 사람은 처음 본 물건이라도 비슷한 형상의 대상을 다른 환경에서 찾아낼 수 있는 능력이 있습니다.
하지만 지금까지의 지도학습 방식에서 모델은 학습에 사용한 형상, 환경에서만 정상적인 작업 수행이 가능합니다.
만약 주어진 데이터의 형상과 추론해야 할 형상이 서로 같지 않다면 어떻게 접근하고 문제를 해결해야 할까요? - 본 과제에서는 낱개의 반도체 부품 이미지 데이터와 빈 기판(PCB) 이미지 데이터를 활용하여 조립된 형상 안에서 각 구성요소를 판별해내는 모델을(Object Detection) 만들게 됩니다.
- 부품과 기판의 구성요소를 바탕으로 조립된 형상에 대한 디텍션이 가능하게끔 할 수 있는 솔루션/모델링/학습방법/데이터 전처리 방식에 대한 아이디어가 과제의 핵심입니다.
- 완벽한 모델이 아니더라도 최대한 가능한 방식을 탐구합니다.
- 데이터에 대한 상세한 설명은 [데이터] 탭을 참조하시면 됩니다.
- [데이터]의 상세 내용은 경진대회 시작 시, 공개 됩니다.
2. 평가 방법 🧪
- 본 대회의 평가에는 목적에 맞게 커스텀된 Macro F1 Score가 사용됩니다.
- mAP가 아니라 F1이므로 참가자분들은 불필요한 중복 예측이 없도록 Non-Max Suppression 혹은 그에 준하는 정리 과정을 적용한 결과물을 제출하셔야 됩니다.

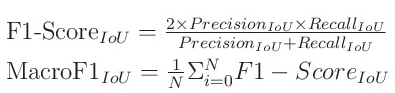
각 항목별 개념은 다음과 같습니다.
- F1 Score 계산 방식:
- 위치와 클래스가 정확히 맞으면 TP
- 둘 중 하나라도 틀리면 FP
- 예측이 만들어지지 않은 레이블은 FN
- Score 산출 과정 설명:
1. 먼저 한 이미지 내의 모든 정답과 모든 예측 사이에 IoU를 계산합니다.
2. 각 예측은 자신과 IoU가 0.5 이상인 정답 가운데 IoU가 가장 큰 정답에 할당됩니다.
- 하나의 예측이 복수 정답에 할당될 수 없습니다.
3. 각 정답은 위 할당 조건을 통과한 하나, 여럿, 또는 0개의 예측과 매칭됩니다.
- 정답에 하나의 예측이 할당된 경우: 클래스도 맞으면 정답 클래스에 TP, 틀리면 FP로 간주합니다.
- 정답에 여러 예측이 할당될 경우: IoU가 가장 큰 예측 하나를 진짜로 간주, 클래스도 맞으면 정답 클래스에 TP, 틀리면 FP 로 간주합니다.
- 나머지 할당되었으나 IoU가 가장 크지 않은 예측들은 각각의 예측 클래스의 FP로 간주합니다.
- 정답이 있으나 아무 예측도 할당되지 않은 경우 해당 정답 클래스에 FN로 간주합니다.
- 아무 정답도 없는 구역에 생성된 예측은 해당 예측 클래스에 FP로 간주합니다.
4. 조건에 따라 macro F1 score를 사용해 점수를 계산합니다.
실제 사용되는 커스텀 스코어 코드는 다음과 같습니다.
import sys
import json
import numpy as np
def intersection_over_union(boxes_labels, boxes_preds):
# coco type label (x0, y0, w, h)
x, y, w, h = boxes_labels
x, y, w, h = float(x), float(y), float(w), float(h)
box1_x1 = float(x)
box1_y1 = y
box1_x2 = x + w
box1_y2 = y + h
x, y, w, h = boxes_preds
box2_x1 = x
box2_y1 = y
box2_x2 = x + w
box2_y2 = y + h
x1 = np.max([float(box1_x1), float(box2_x1)])
y1 = np.max([float(box1_y1), float(box2_y1)])
x2 = np.min([float(box1_x2), float(box2_x2)])
y2 = np.min([float(box1_y2), float(box2_y2)])
intersection = max((x2 - x1), 0) * max((y2 - y1), 0)
box1_area = abs((box1_x2 - box1_x1) * (box1_y2 - box1_y1))
box2_area = abs((box2_x2 - box2_x1) * (box2_y2 - box2_y1))
epsilon = 1e-6 if box1_area + box2_area - intersection == 0 else 0
return intersection / (box1_area + box2_area - intersection + epsilon)
def macro_f1(gt, pr, th=0.5):
tp = np.zeros(len(gt['categories']), dtype=int)
fp = np.zeros(len(gt['categories']), dtype=int)
fn = np.zeros(len(gt['categories']), dtype=int)
tp_p = np.zeros(len(gt['categories']), dtype=int)
fp_p = np.zeros(len(gt['categories']), dtype=int)
fn_p = np.zeros(len(gt['categories']), dtype=int)
for img in gt['images']:
gt_img = [i for i in gt['annotations'] if i['image_id'] == img['id']]
pr_img = [i for i in pr['annotations'] if i['image_id'] == img['id']]
# print(pr_img)
tp_temp = np.zeros(len(gt['categories']), dtype=int)
fp_temp = np.zeros(len(gt['categories']), dtype=int)
fn_temp = np.zeros(len(gt['categories']), dtype=int)
# 해당 GT 이미지에 object가 있고
if len(gt_img) > 0:
gt_classes = [i['category_id'] for i in gt_img]
# 해당 GT 이미지에 대한 예측이 있는 경우
if len(pr_img) > 0:
ious = [intersection_over_union(i['bbox'], j['bbox']) for i in gt_img for j in pr_img]
# pr을 iou가 최대인 gt에 할당
ioumat = np.array(ious).reshape(len(gt_img), -1) # gt_dim:0, pr_dim:1
# assigned_indices = np.argmax(ioumat, axis=0) # pr을 gt에 할당해야 하므로
ioumat = ioumat * (ioumat.max(axis=0, keepdims=True) == ioumat)
# TP / FP / FN
pr_classes = [i['category_id'] for i in pr_img]
for i in range(len(gt_classes)):
assigned = sum(ioumat[i] >= th) # 할당 기준은 th 이상일 것
if assigned == 0: # 아무 오브젝트에도 예측되지 않은 정답은 해당 클래스 FN에 더함
fn_temp[gt_classes[i]] += 1
else:
if assigned > 1:
fp_temp[gt_classes[i]] += assigned - 1 # 중복 예측은 FP에 할당
if gt_classes[i] == pr_classes[ioumat[i].argmax()]:
tp_temp[gt_classes[i]] += 1
# 무엇에도 assign되지 않은 예측(모든 obj와 iou가 th 미만)은 해당 예측의 class에 FP로 더함
unassigned = np.where([np.all(ioumat[:,i] < th) for i in range(len(pr_classes))])[0]
if len(unassigned) > 0:
for j in unassigned:
fp_temp[pr_classes[j]] += 1
# 해당 GT 이미지에 대한 예측이 없는 경우 모든 object를 FN에 추가
else:
for i in range(len(gt_classes)):
fn_temp[gt_classes[i]] += 1
# 해당 GT 이미지에 아예 object가 없는 경우
else:
# 해당 GT 이미지에 대한 예측이 있는 경우 모든 예측을 FP에 추가
if len(pr_img) > 0:
pr_classes = [i['category_id'] for i in pr_img]
for i in range(len(pr_classes)):
fp_temp[pr_classes[i]] += 1
# 전체 TP, FN, FN에 결과 추가
if img['id'] in public_id:
tp_p += tp_temp
fp_p += fp_temp
fn_p += fn_temp
else:
tp += tp_temp
fp += fp_temp
fn += fn_temp
# macro 계산
precision_p = tp_p / (tp_p + fp_p)
recall_p = tp_p / (tp_p + fn_p)
f1_score_p = (2 * precision_p * recall_p) / (precision_p + recall_p)
# nan -> 0 추가
f1_score_p[np.isnan(f1_score_p)] = 0
f1_score_p = np.nanmean(f1_score_p)
precision = tp / (tp + fp)
recall = tp / (tp + fn)
f1_score = (2 * precision * recall) / (precision + recall)
# nan -> 0 추가
f1_score[np.isnan(f1_score)] = 0
f1_score = np.nanmean(f1_score)
return f1_score_p, f1_score
3. 결과 검증 🔍
- 입상 대상자는 아래 저작물을 제출해야 합니다.
- 모델 학습 코드 : 구글 Colab에서 작동하는 train.ipynb 및 필요한 파일(외부 파일 등) 공유
- 모델 추론 코드 : 구글 Colab에서 작동하는 test.ipynb 및 필요한 파일(모델 가중치 등) 공유
- 모델 설명서 : 아래 양식에 맞게 작성 후 입상후보팀에게 안내되는 메일에 회신으로 전달
- 코드와 주석의 인코딩은 모두 UTF-8을 사용하여야 합니다.
- 입상 대상이 되는 상위 제출 결과물은 재현성 검증 과정을 거쳐 순위를 확정짓게 됩니다.
재현성 검증은 다음 세 단계를 거쳐 이루어집니다.- 재추론 검증
- 제출된 모델에서 주어진 데이터를 이용하여 결과가 정상 생성되는지 여부를 확인할 수 있도록 재추론합니다.
- 원칙적으로 재추론을 통해 생성된 결과는 참가자가 실제 제출한 결과와 동일해야 합니다.
- 재학습 검증
- 제출된 모델이 허가된 데이터만을 사용하여 학습되었는지, 학습된 모델은 제출된 결과를 재현할 수 있는지의 여부를 재학습을 통해 검증합니다.
- 소스코드 분석
- 소스코드 표절, 미허가 데이터 사용, 모델 조건 불충족 여부 등을 소스코드 분석을 통해 검증합니다.
- 재추론 검증
- 재현성 검증에 문제가 발생하거나 소스코드 표절을 비롯한 치팅이 확인되는 경우 원칙적으로 해당 제출 결과는 무효처리됩니다.
4. 대회 규칙 (중요) 📜
※ 본 대회는 http://aifactory.space 의 회원가입을 완료한 회원이 아래 규칙에 대해 동의한 경우에만 참가 가능합니다.
※ 대회 참여 중 규칙에 위배되는 상황이 발생한 경우, 입상이 취소될 수 있습니다.
스코어 관련
이번 대회는 Public 스코어와 Private 스코어 total 점수로 최종 순위가 결정됩니다
- Public 및 Private의 비율은 1:1
- 대회기간 중에는 Public 스코어만 리더보드 상에 표출
- 대회 종료시점 이후 Public 및 Private의 total 점수 및 그에 따른 최종 순위 공개
팀 참가 관련
- 팀(2인 이상 최대 4인), 최소 1인 이상 (✽팀 빌딩은 참가신청 이후에 [팀] 탭에서 진행하실 수 있습니다)
- 팀 구성시 USG 공유대학 학생 1인 이상 참여 필수
대회 제출 관련
- 해당 문제는 제출 관련 제한사항이 있습니다. 이전 제출 시점 기준으로 3시간 지난 시점부터 재제출이 가능하오니 이 점 참고 부탁드립니다.
- 본 대회에서 외부 데이터는 문의 후 허가 확인이 된 파일만 사용이 가능합니다. 공정성 검토 결과에 따라 한 팀이 사용 요청한 외부 데이터가 전체 팀에게 사용 가능하도록 공개될 수 있으니 이점 참고바랍니다.
- 본 대회에서는 pre-trained 모델 사용이 가능합니다.
- 검증시에는 사용한 모든 데이터를, 전처리부터 처리과정의 모든 코드를 포함하여 스코어를 기록한 조건의 모델 학습/추론 코드와 함께 제출하여야 합니다.