
안녕하세요!
LangChain KR x NAVER Cloud 생성형 AI 서비스 프로젝트 기간이 얼마 남지 않았습니다.
진행하시는 분들 모두 끝까지 화이팅하시길 바랍니다!
서비스 개발에 도움이 되었으면 하는 마음으로, CLOVA OCR 서비스를 사용하는 방법에 대해 공유하고자 합니다!
NAVER Clova OCR 서비스 신청하기
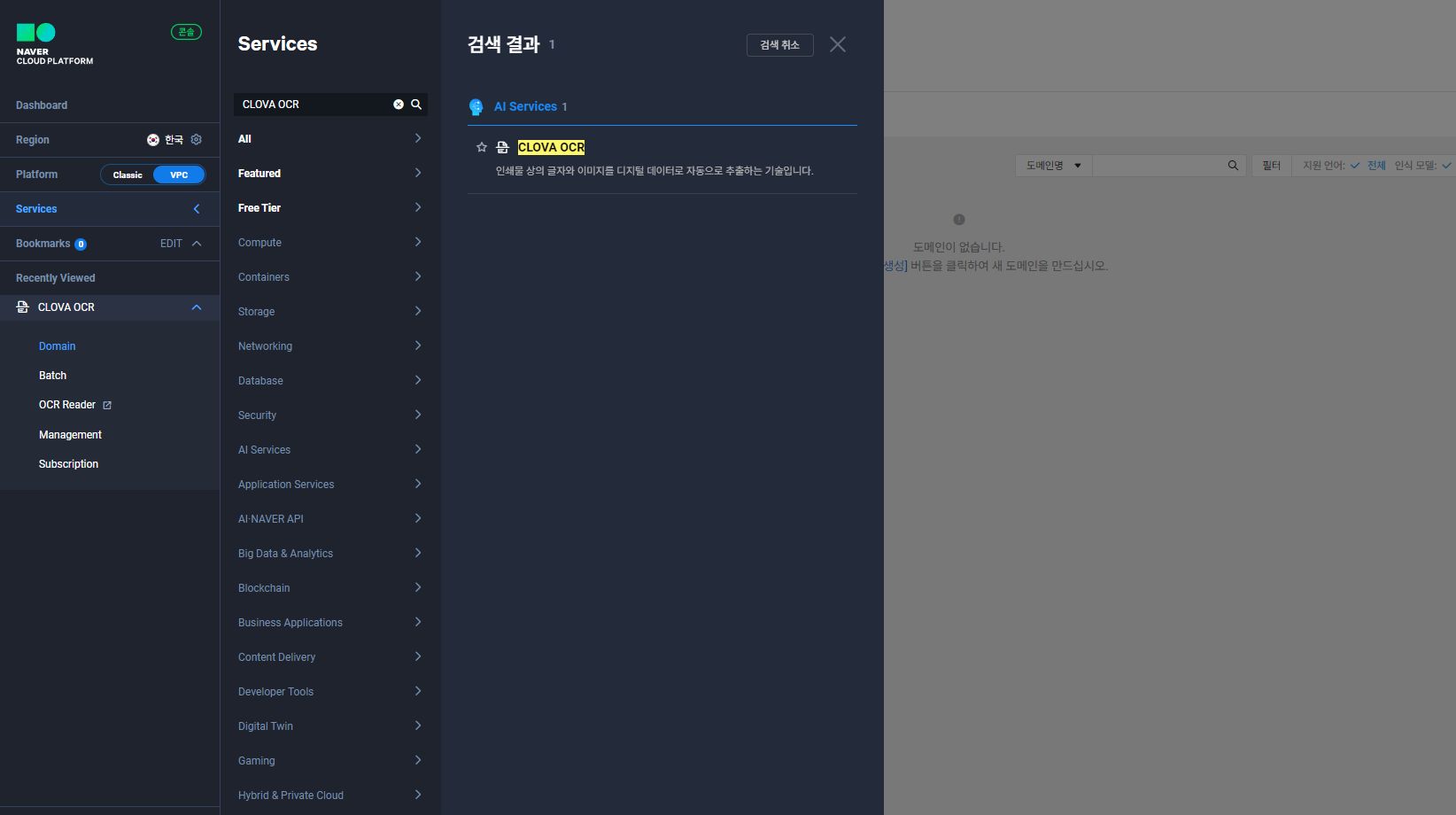
먼저, 콘솔에 들어가 CLOVA OCR 서비스로 들어가줍니다.
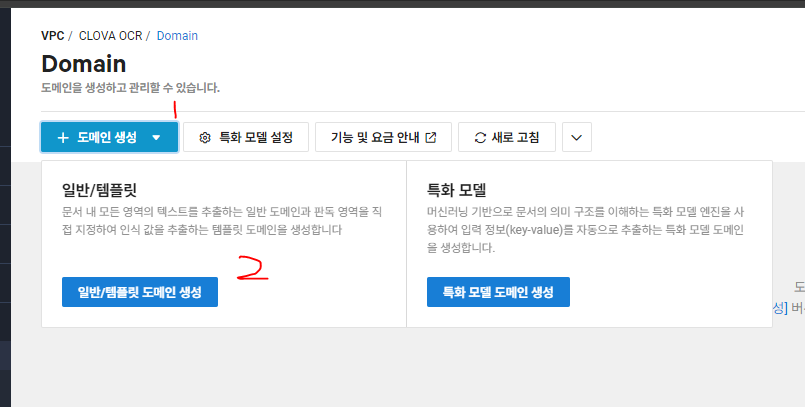
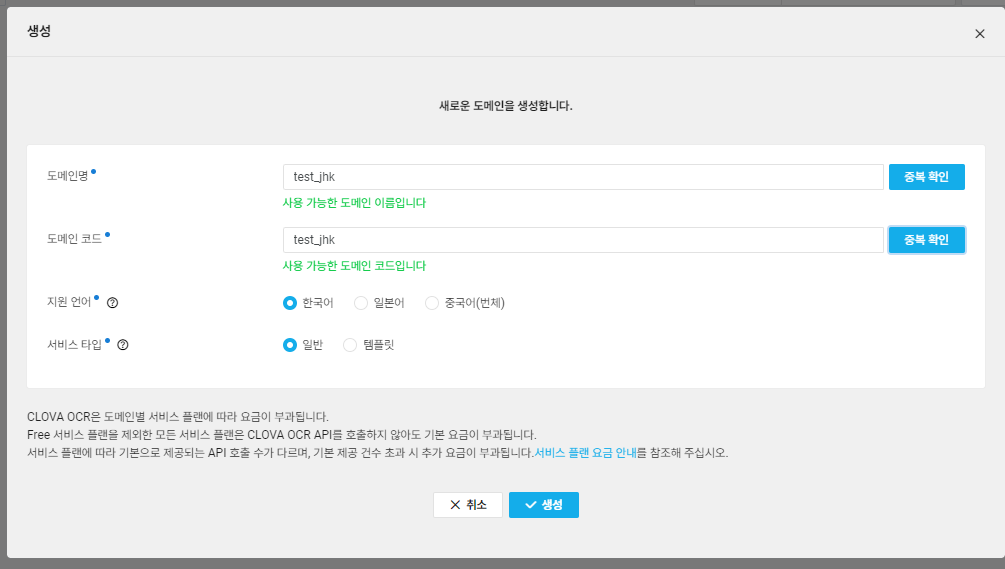
일반/템플릿 버전으로 도메인을 생성해주고, 도메인명을 아무렇게나 만들어줍니다.

도메인이 잘 생성되었는데, 이제 API Gateway와 연동을 해야합니다.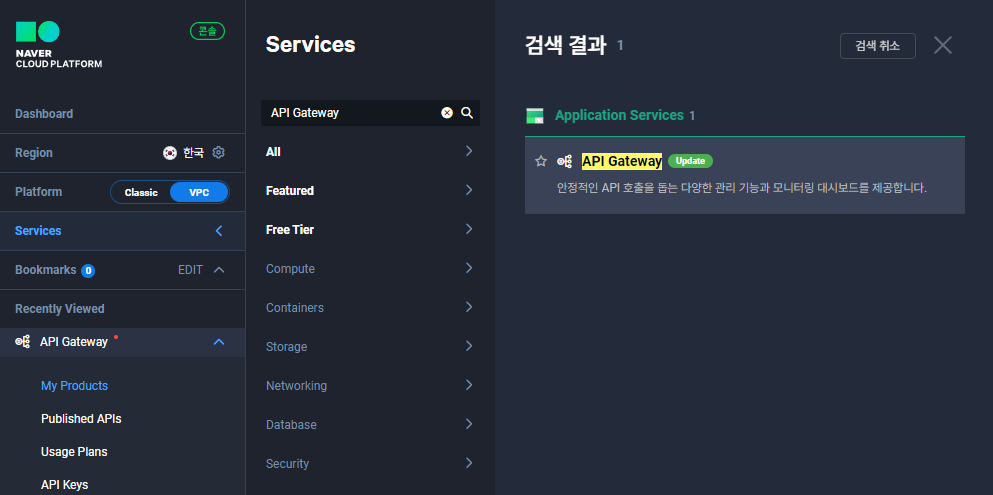
그전에! 먼저 API Gateway를 검색해서, 사용신청이 되어있는지 확인해주세요.
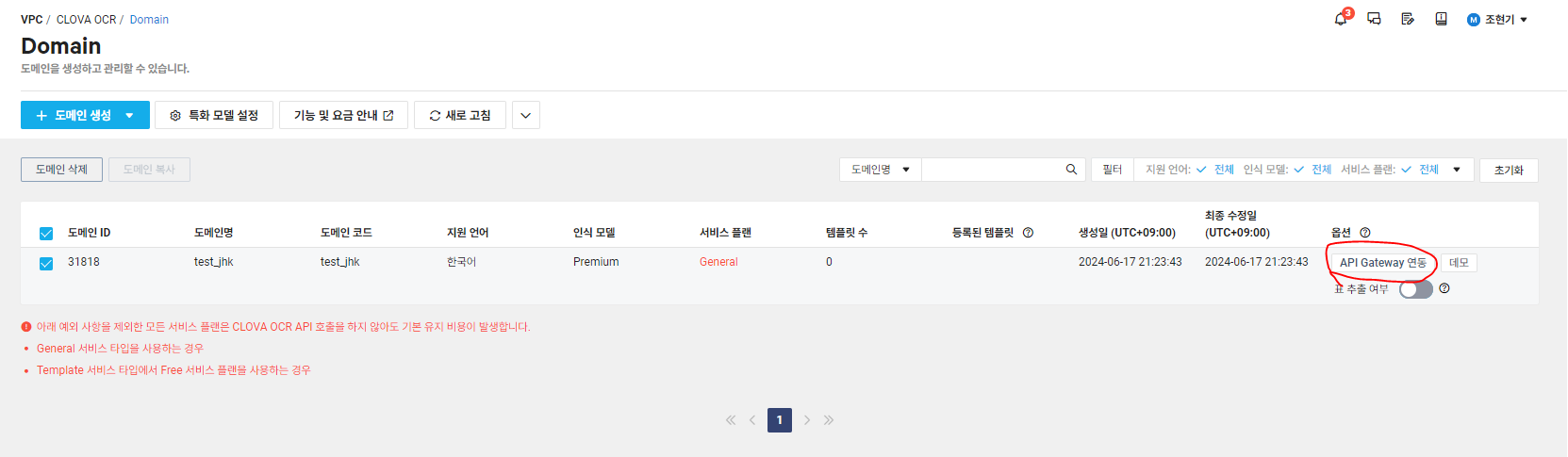
API Gateway 사용신청이 되어있다면, 이제 CLOVA OCR에서 API Gatewayt 연동 버튼을 클릭해줍니다.
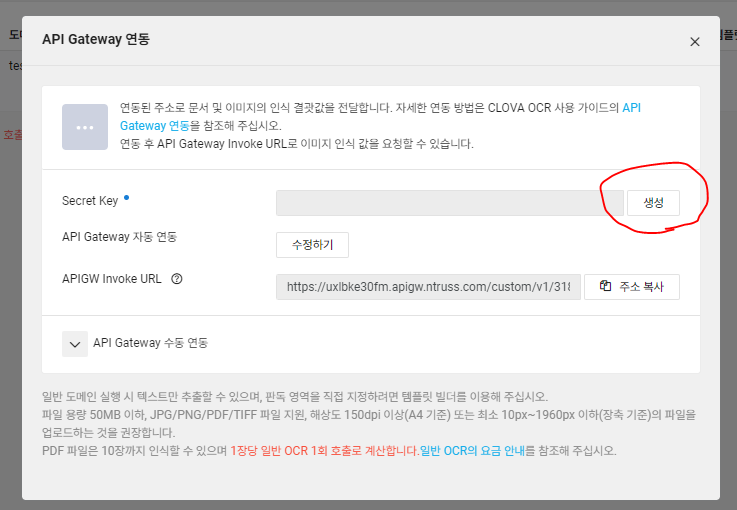
위 화면에서 Secret Key를 생성하고, APIGW Invoke URL도 확인할 수 있습니다!
만약 이 화면이 나오지 않고 API Gateway 자동연결 버튼이 나온다면, 자동연결 버튼을 눌러 API Gateway와 연동해주시면 되겠습니다.
Google Colab에서 사용해보기
import time
import pandas as pd
import cv2
import json
import matplotlib.pyplot as plt
import shutil
import os
import random
from PIL import Image
import requests
import uuid
import time
import json
############################ Edit!
secret_key = 'Secret Key'
api_url = 'APIGW Invoke URL'
image_file = 'Image path'
############################
# Setting up the request JSON
request_json = {
'images': [
{
'format': 'jpg',
'name': 'demo'
}
],
'requestId': str(uuid.uuid4()),
'version': 'V2',
'timestamp': int(round(time.time() * 1000))
}
payload = {'message': json.dumps(request_json).encode('UTF-8')}
files = [('file', open(image_file,'rb'))]
headers = {'X-OCR-SECRET': secret_key}
# Make the OCR request
response = requests.request("POST", api_url, headers=headers, data=payload, files=files)
# Load the original image for visualization
image = cv2.imread(image_file)
highlighted_image = image.copy()
# OCR 응답 처리
if response.status_code == 200:
ocr_results = json.loads(response.text)
all_texts = [] # 모든 텍스트를 저장할 리스트
for image_result in ocr_results['images']:
for field in image_result['fields']:
text = field['inferText']
all_texts.append(text) # 텍스트 추가
# 텍스트 주변에 빨간 사각형 그리기
bounding_box = field['boundingPoly']['vertices']
start_point = (int(bounding_box[0]['x']), int(bounding_box[0]['y']))
end_point = (int(bounding_box[2]['x']), int(bounding_box[2]['y']))
cv2.rectangle(highlighted_image, start_point, end_point, (0, 0, 255), 2)
# 모든 텍스트를 띄어쓰기로 연결하여 출력
full_text = ' '.join(all_texts)
print(full_text)
else:
print(f"OCR 결과를 받아오지 못했습니다. 상태 코드: {response.status_code}")
# Display the original and highlighted images side by side
fig, axs = plt.subplots(1, 2, figsize=(15, 10))
axs[0].imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
axs[0].set_title('Original Image')
axs[0].axis('off')
axs[1].imshow(cv2.cvtColor(highlighted_image, cv2.COLOR_BGR2RGB))
axs[1].set_title('Highlighted Image')
axs[1].axis('off')
plt.show()output
제품명 한우 소불고기 전골 식품유형 간편조리세트(가열하여 섭취하는 냉동식품) 소비기한 제품 별도 표기일까지 품목보고번호 202003630271059 소스[양조간장(탈지대두/오국산), 설탕, 양파(국산), 마늘, 청주], 소고기(설도, 한우/국산), 숙면[밀가루 원재료명 (밀/호주산), 전분가공품{감자전분(독일산 99 %, 국산 1 %)}, 면류첨가알칼리제(정제수, 탄산나트륨, 탄산수소나트륨), 정제소금], 팽이버섯, 양파, 대파 대두, 밀, 쇠고기 함유 제조원 (주)프레시지/경기도 용인시 처인구 이동읍 삼배울로 23 보관방법 -18°C 이하 냉동보관 반품 및 교환 구입처 및 판매원 내포장재질 PE 고객상담전화 1833-5836

CLOVA OCR은 한국기업인 NAVER에서 제공하는 서비스라 그런지, AWS나 GCP에 비해 한글을 잘 찾아주는 것 같습니다.
바운딩 박스를 봐도, 곂치는부분 없이 깔끔합니다.
사용하실 때는, 위 코드에서 secret_key, ,api_url, image_file 를 수정하면 됩니다!
이 글이 도움이 되셨으면 좋겠습니다.
감사합니다!