
안녕하세요.
멀티모달 데이터를 융합할 때, 모달리티마다 성능에 영향을 미치는 데이터와 아닌 데이터가 있을 수 있습니다.
이때, 온도 모듈을 적용하면 더 효과적인 멀티모달 학습이 가능하지 않을까 싶어, 논문을 소개합니다
Curriculum Temperature for knowledge Distillation
저자
Zheng Li 1, Xiang Li 1*, Lingfeng Yang 2, Borui Zhao 3, Renjie Song 3, Lei Luo 2, Jun Li 2, Jian Yang 1*
1 Nankai University
2 Nanjing University of Science and Technology
3 Megvii Technology
Abstract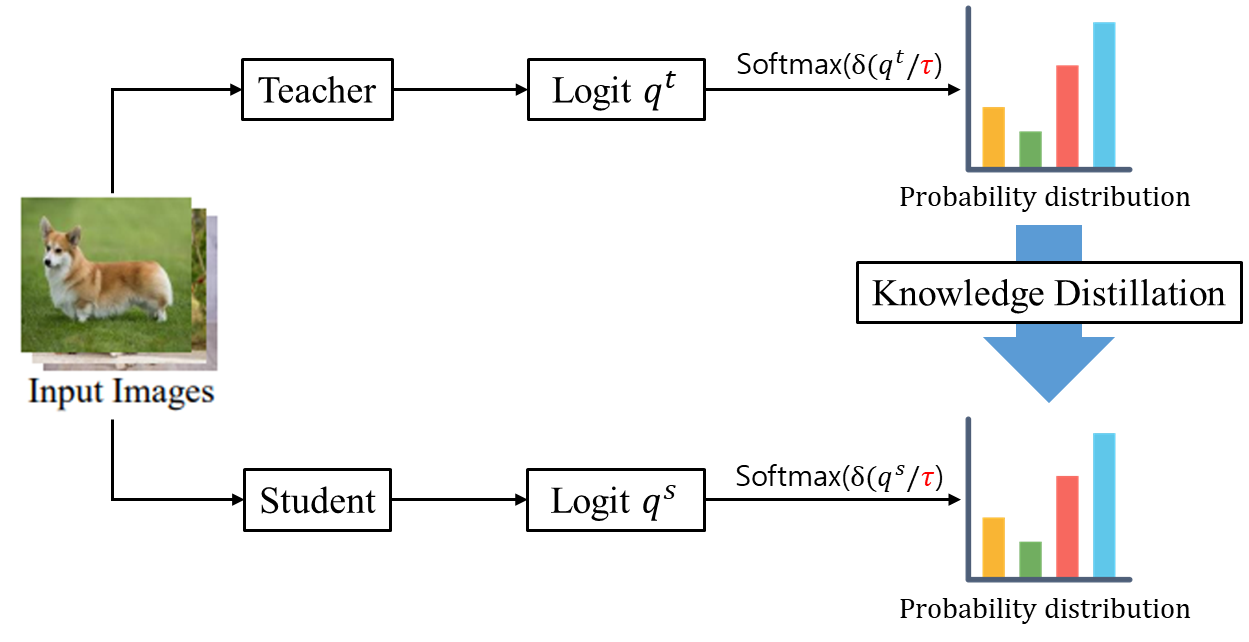
대부분의 기존 증류 방법은 손실함수에서 온도 (Temperature) 의 유연한 역할을 무시하고, 이를 단순한 하이퍼 파라미터로 간주한다. 그러나, 온도는 두 분포 사이의 불일치를 제어하고 증류 작업(Distillation task)의 난이도(difficulty)를 제어할 수 있다. 본 논문에서는, 가변적이고 학습 가능한 온도를 통해 학생의 학습동안 난이도 수준을 제어하는 간단한 curriculum기반 CTKD(Curriculum Temperature for Knowledge Distillation)를 소개한다.
Method
Background
모델 압축에서 주력기술 중 하나인 지식증류 (Hinton, Vinyals, and Dean 2015)는 Vision 작업에서 매우 폭넓게 사용되고 있다 (Liu et al. 2019; Ye et al. 2019; Li et al. 2021b, 2022). 전통적인 two-stage 증류 방법은 주로 미리 훈련된 번거로운 교사모델로 시작한다. 그 다음, 작은 학생 네트워크는 부드러운 예측(soft predictions) 또는 중간표현(intermediate representation, Romero et al. 2014; Yim et al. 2017) 를 이용한 교사 네트워크의 감독아래 훈련된다. 주어진 라벨링된 데이터셋 D={(x_i, y_i)}^I_{i=1}에서 , KL 발산손실 (Kullback-Leibler divergence loss) 은 아래 공식과 같이, 교사와 학생 모델의 부드러운 출력 확률 (soft output probabilities) 간의 불일치를 최소화하는데 사용된다.
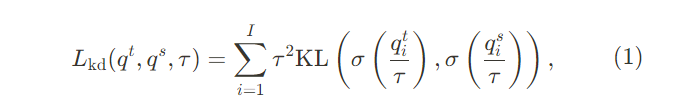
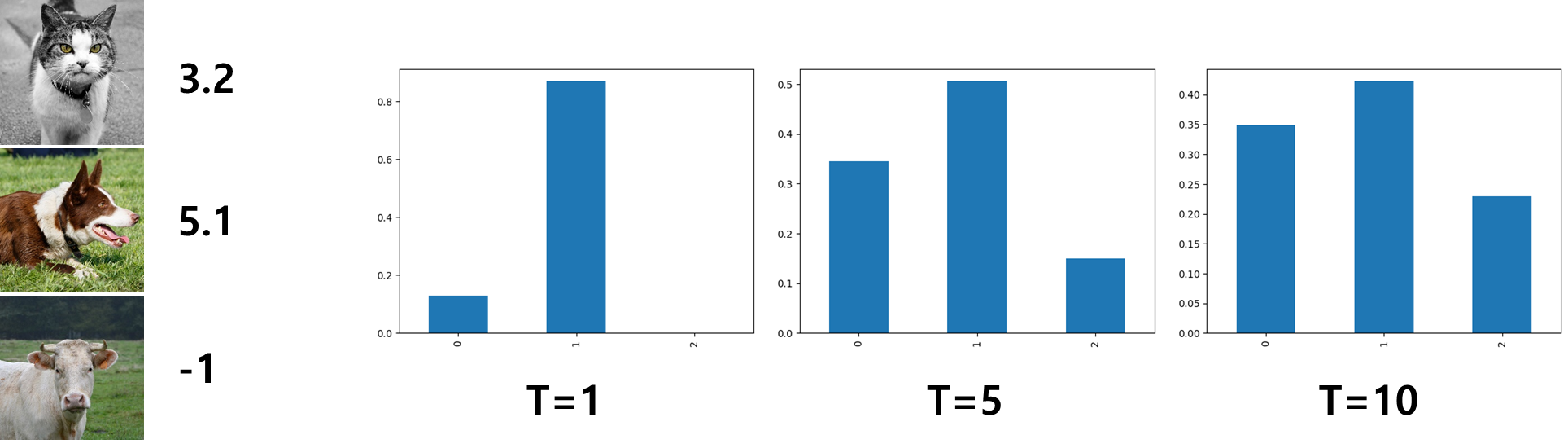
이때 qt와 qs는 각각 교사와 학생의 logits을 의미하고, σ(·) 는 softmax 함수, τ는 두 분포를 부드럽게 스케일하는 온도를 표시한다. 아래 그림과 같이, τ가 작을수록 분포가 날카로워지고, 두 분포간의 차이를 크게하며, 교사의 예측의 최대 로짓에 증류의 초점이 맞춰진다. 반대로 τ가 크면 분포를 더욱 평평하게 하여, 두 모델 사이의 격차를 좁게하고 교사의 전체 로짓에 증류의 초점을 맞추게 된다. 그러므로, 온도(τ)는 확률분포에 영향을 미쳐. 신뢰도 있게 지식증류 손실 (KD loss) 의 최소화 과정의 난이도를 결정한다.
Adversarial Distillation

기본 지식증류에서는 학생모델은 특정작업 손실(Task-specific loss)와 증류 손실 (Distillation loss) 를 최소화하여 최적화 되었다. 이 증류 과정의 목적은 다음과 같이 공식화 된다.
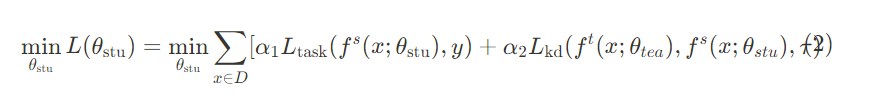
이때, Ltask는 이미지 분류 작업에서 사용되는 일반 cross-entropy 손실이고, ft(), fs()는 교사와 학생의 함수이다.
동적 온도로 학생의 학습 난이도를 제어하게되므로, GAN에 영감을 받아 (Goodfellow et al. 2014), 본 논문은 현재 훈련에 적합한 온도 τ를 예측하는 동적 온도 모듈에 대한 적대적 학습을 제안한다. 이 모듈은 학생과 반대 방향으로 최적화되어, 학생과 교사의 증류손실을 최대화한다.

즉, 아래와 같이 학생모델은 loss를 최소화하고, 온도모듈은 loss를 최대화 한다.

Curriculum Temperature

학교에서, 선생님은 언제나, 쉬운 개념으로 시작하여 학생들이 성장할 수록 점점 어려운 개념으로 커리큘럼을 설계하고, 이를 따라 학생을 가르친다. 사람은 의미있는 순서로 정렬된 작업을 할 때, 훨신 잘 학습할 수 있다. 이러한 커리큘럼 러닝 (Curriculum learning, Bengio et al. 2009) 에 영향을 받아, 저자는 손실 L을 크기 \lambda로 직접 스케일링하여 쉬운 것부터 어려운 것으로 증류작업이 구성 되어있는 간단하고 효과적인 커리큘럼을 제안한다. 즉, 온도 모듈은 다음과 같이 업데이트 된다.
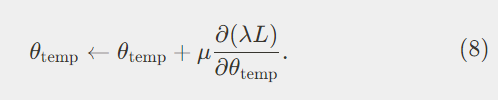
훈련의 시작에는 어린 학생은 표현능력의 한계 (Limited representation ability)가 있으며, 기본적인 지식을 요구한다. 이때, 초기 lambda를 0으로 설정하여 어린 학생이 아무런 제약없이 학습에 집중할 수 있도록 한다. lambda를 점진적으로 상향시킴으로, 증류의 난이도를 높혀서 학생이 더 고급 지식을 학습할 수 있도록 할 수 있다.
Experiments
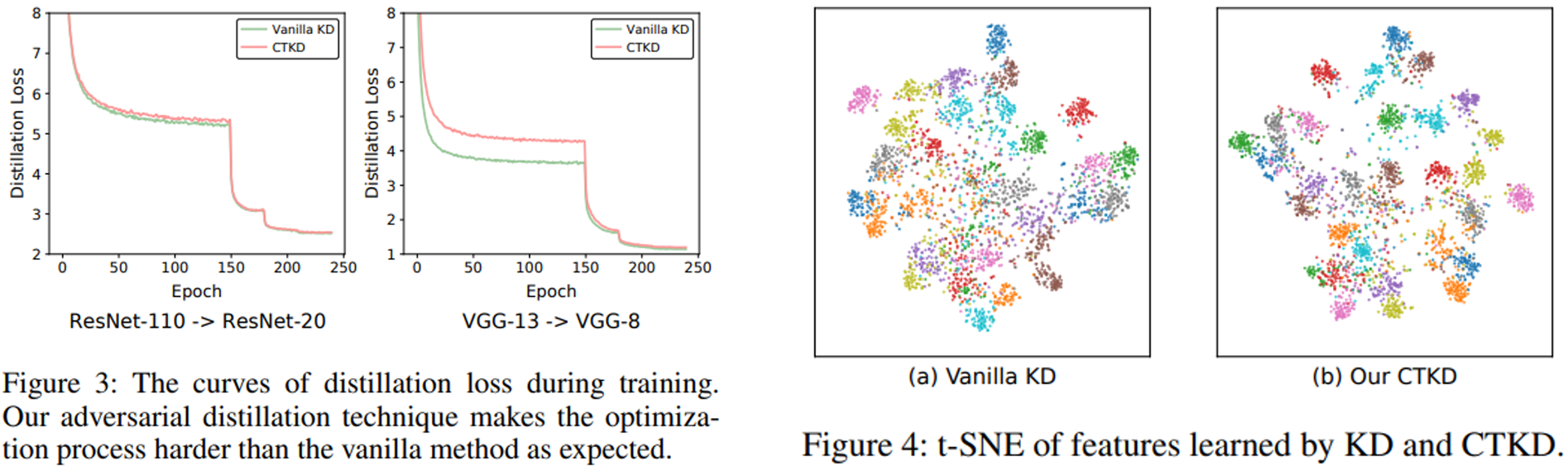
CIFA-100으로 실험을 진행했을 때, 그림 3에서 CTKD가 기존의 VanilaKD보다 중간 loss가 높지만, 최종 에포크에서는 유사하게 수렴했다. 또, 그림 4에서 기존 VanillaKD보다 더 효과적으로 분산되었다. 이는 CTKD가 더 디테일한 피처를 학습하여, 더 깊은 피처를 식별 가능하게함을 의미한다.
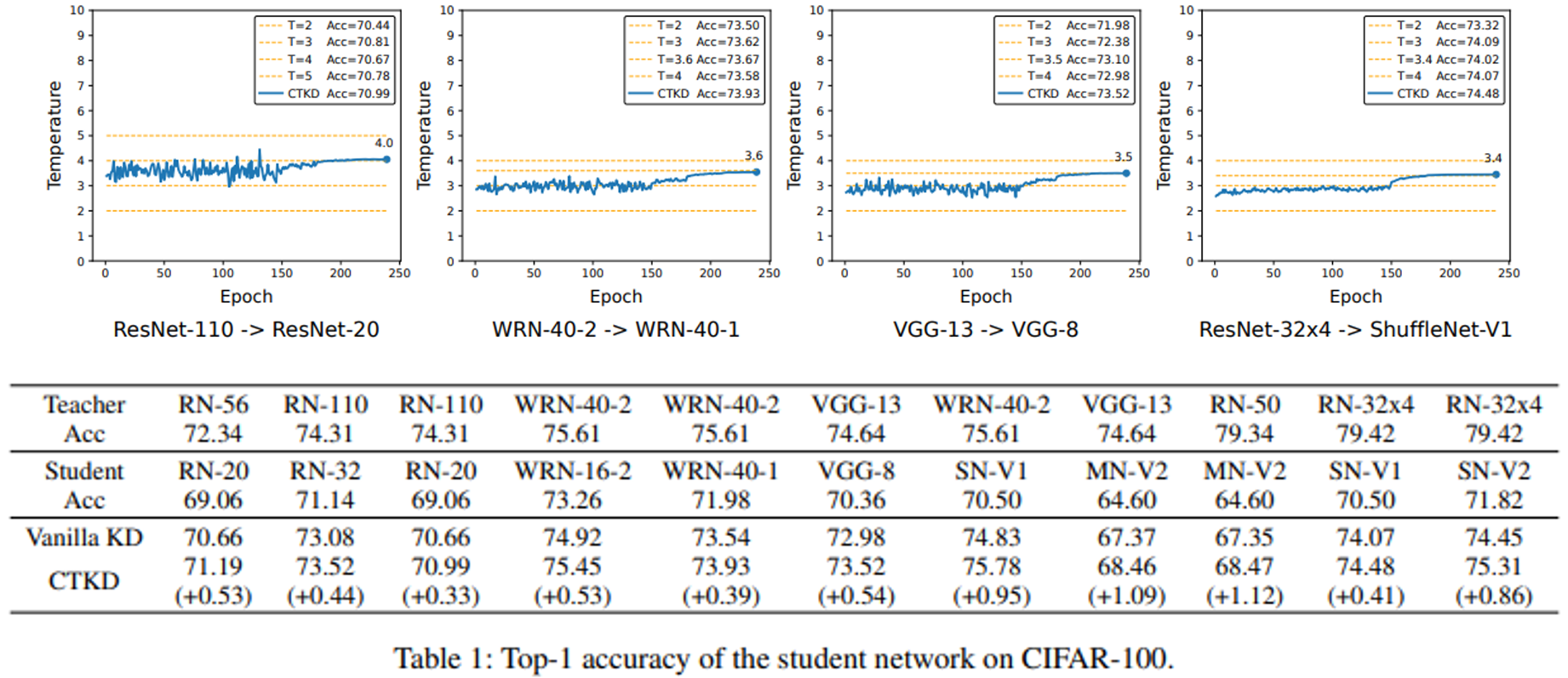
위 그림은 학습 중에 온도의 학습 곡선을 보여준다. 온도를 고정한 증류와 비교하여, 논문의 CTKD는 온도를 동적으로 제어하고 있으며, 기존 방법보다 좋은 성능을 보인 것을 확인할 수 있다. 또, 아래 표는 다양한 모델에 대해 기존 KD방법과 CTKD를 적용한 후의 성능 비교이다.
마치며,
CTKD방법은 성능을 극적으로 끌어올리진 않습니다. 그러나, 기존 방법에 쉽게 적용 가능하면서, 추가적인 계산비용없이 이렇게 성능을 향상시킬 수 있다는 점이 본 논문의 의의라고 생각합니다.
또, 지식증류뿐만이 아니라, 멀티모달리티를 융합할 때도 적용할 수 있습니다. 온도모듈을 통해 성능에 부정적인 영향을 주는 모달리티는 온도를 높혀 최종결과에 반영하지 않고, 성능에 긍정적인 영향을 주는 모달리티만 남기면, 모델의 최종성능에도 도움이 될 것입니다.