
1. 서비스 배경 및 목적
- 짧은 시간 안에 긴 글의 내용을 명료하게 이해하기 위한 도구가 필요
- ChatGPT를 사용한 요약이 가능하지만 한국어를 완벽하게 구사하지 못함
- 본인이 잘 알지 못하는 문헌의 경우 필요한 내용을 뽑아낼 수 있음
2. 인공지능 서비스 유사 사례 분석
- OpenAI의 ChatGPT 사례 https://openai.com/blog/chatgpt
- kakao brain의 KoGPT 사례 : 한국어 기반의 언어 모델 https://developers.kakao.com/product/kogpt
- Naver의 하이퍼클로바엑스(X) 출시 예정 https://www.hani.co.kr/arti/economy/it/1081381.html
- BERT SUM의 한국어 버전(KoBertSum) https://github.com/uoneway/KoBertSum
3. 인공지능 모델의 입출력
- 입력 : 텍스트 (파일형식: json)
- 출력 : 텍스트 (입력의 요약된 텍스트)
4. 데이터셋 구축방안
- BICrawler 웹 수집기 활용한 데이터 수집
- 출판사의 파일 제공을 통한 데이터 확보
- 문헌 구입
5. 데이터셋 구성 목표
- Train/Validation/Test
- Train set : 146,771
- Validation set : 18,300
- Test set : 18,304
- Total : 183,375
- 데이터 종류별 구분
- 뉴스 27,000
- 보도자료 20,002
- 역사기록물&문화재 10,002
- 보고서 10,000
- 회의록 34,000
- 사설 10,000
- 간행물 10,000
- 연설물 40,000
- 문학 12,000
- 나래이션 10,371
6. 인공지능 모델 평가 방법
- ROUGE-N score = 정답 summary와 생성된 summary 사이의 n-gram recall
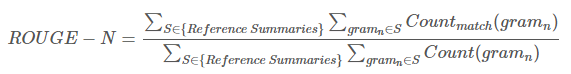
7. 인공지능 모델 성능 목표
- TBA [baseline score]
8. 서비스 구축계획 및 사용 시나리오
- 그라디오를 활용한 웹 인터페이스 구성
- 입력 : 텍스트 입력 or 파일 업로드(txt,csv ..)
- 출력 : 텍스트
9. 서비스 기대효과
- 본문을 자동으로 요약하여 ‘세 줄 요약’ 같은 서비스 제공 가능
- 도서/논문을 요약하여 간단히 볼 수 있는 서비스 제공 가능
- 바쁜 현대인을 위해 리딩북, 뉴스 서머리 등 몰아보기 서비스 제공 가능
10. Reference
- AIHub 요약문 및 레포트 생성 데이터 https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=582