
⚠️필수사항
- 안내 페이지 상단에 참여하기 클릭후 신청폼 완료하신 분에 한하여, 해당 대회가 참여 가능하며 리더보드 제출 이력을 인정합니다.
- 팀으로 신청하신 분들께서는 해당 태스크 팀 탭 에서 팀 빌딩을 완료해주시기 바랍니다. (팀 병합 마감일은 5월 4일 목,18시 까지) 입니다.
- 해당 태스크에서 참여하기를 클릭하신후 개요/데이터 탭 확인하신후 리더보드 제출이 가능합니다.(1시간 1번 제출,1시간 간격으로 재제출 가능)
- 개인/ 팀 택 1로, 중복해서 참여 불가
🎈 대회 주제 소개
■ 지역사회 대기오염 예측 인공지능 모델 개발
- 대덕특구 50주년을 맞아 탄소중립 과학기술 도시실현을 위한 혁신의 장을 개최합니다!
- 대전·세종·충남 지역 초미세먼지(PM2.5) 오염도를 시간단위로 예측하는 모델을 만드는 것이 본 과제의 목표입니다.
- 데이터의 연도/시간/값은 비식별화 되어있습니다.
- 데이터의 위치는 다음과 같습니다. (청색: AWS 측정소 / 적색: PM2.5 측정소)
🎓문제 및 모델 조건 (중요)
1. 2일 분량의 PM2.5 / AWS 데이터(test set)와 과거 기간의 PM2.5 / AWS 데이터 (train set)을 활용하여 3일 분량의 지역별 시간당 PM2.5 값을 예측합니다.
2. PM2.5 예측에 AWS값이 반드시 사용되어야 합니다. AWS 값을 사용하지 않은 모델은 무효처리됩니다.
3. 앙상블 규정 (설명 보충)
- 모든 관측소에 대하여 같은 모델로 예측을 수행해야 하며
- 복수 모델의 추론 결과를 평균/가중합/투표하여 답안을 생성하는 형태 등의 결과적 앙상블을 허용하지 않습니다.
- 다만, 추론 중간 과정에서 대상 요소별로 별도의 모델을 사용하고 추론된 결과를 다시 별도의 모델에 입력하여 결과를 만들어내는 경우(예: 기온 예측 모델, 습도 예측 모델을 만들고 예측된 기온과 습도를 이용하여 PM2.5를 예측하는 모델 등)는 하나의 모델이 여러 단계의 입력을 받아 결과를 생성하는 것으로 보아 허용됩니다. 대신 이 경우 추론 수행 시에는 최초 입력으로부터 최종 결과 생성까지의 과정에 인위적인 개입이 없이 seamless한 pipeline으로 연결될 수 있어야 합니다.
- 핵심은 앙상블 모델 금지, 그리고 관측소별로 별도의 모델(해당 관측소 외에는 사용 불가능한 전용 모델)을 만드는 것이 아니라 global한 모델을 만드는 것을 목표로 해야 한다는 것입니다.
4. train set을 test set 예측에 사용할 수 있습니다. 하지만 test set을 모델 학습에 사용할 수 없습니다.
📌 대회 규칙
※ 아래 내용에 대해서 동의 후 대회 참가할 수 있으며, 아래 사항이 만족 되지 않을 경우 입상이 취소될 수 있음.
1. 데이터 관련
- 주어진 데이터셋 이외의 모든 외부 데이터 사용을 일체 금지합니다.
- 본 대회의 사용 데이터는 공공 데이터로 일정 수준 비식별화가 되어있으며 , 공정성을 위해 엄격하게 부정행위 방지 및 재현성 검증이 이루어집니다. 모델로부터 생성되지 않은 인위적 수정이 가해진 결과물과 주어진 데이터 외의 데이터를 사용하여 학습이 이루어진 결과물은 원칙적으로 무효처리됩니다.
- 제공되는 데이터셋을 이용하여 최초 학습단계에서부터 모델을 재학습하여 결과가 재현되는지 여부를 검증하므로 코드/가중치/하이퍼파라미터/seed 설정 등의 조건에 따른 버전 관리를 철저히 하여 검증 실패로 인한 불이익이 없도록 합니다.
2. 팀 참가 관련
- 한 팀의 인원 제한은 최대 4명
- 제출은 반드시 팀 대표 1인의 아이디로 제출
- 팀이 수상하는 경우 팀 대표에게만 상금 지급
3. 제출 관련:
- 제출 이후 1시간 이내에는 다시 제출하실 수 없습니다.
4. 스코어 관련
- 별도의 Private Score 없이 Public Score로 진행됩니다.
5. 결과 검증 관련
- 아래 결과 검증 참조
🔍 결과 검증
- 입상 후보팀으로 선정되는 경우 아래 저작물을 제출해야 합니다.
- 작성 코드 : *.ipynb로 작성하고 필요한 내용에 대해 주석을 기입하여 1회 제출
- 반드시 리더보드상의 순위 기록에 해당되는 버전의 코드/모델 가중치를 제출해야 합니다.
- 학습용 소스와 추론용 소스를 별도의 파일로 분리 작성(ex: train.ipynb, predict.ipynb)
- 모델 및 소스코드에 대한 설명은 ipynb 안에 기재
- 아키텍처를 커스텀한 경우는 반드시 모델 구조에 대한 설명을 포함해야 합니다. - 모델 weight 또는 저장된 모델 : 딥러닝 계열로 weight가 파일로 저장되는 경우 저장된 weight를, 그 밖의 경우는 pickle/joblib 등의 라이브러리를 이용해 dump한 모델
- 작성 코드와 weight는 cs@aifactory.page 로 일괄 접수
- 작성 코드 : *.ipynb로 작성하고 필요한 내용에 대해 주석을 기입하여 1회 제출
- 입상자가 제출한 코드는 공지된 검증 기간 내 구동 및 성능에 대한 재현성 검증이 되어야 합니다.
- 모든 코드는 오류 없이 실행되어야 함.
- 소스코드 내의 모든 무작위성은 seed 설정을 통해 통제되어야 함.
- 별도 필요한 라이브러리가 있을 경우 소스코드 내에 설치하는 코드가 있어야 함.
- 원활한 코드 구동 및 성능 재현성 검증을 위해 필요한 최소한의 주석 혹은 가이드가 제공되어야 함.
- 재현성 검증은 다음 세 단계를 거쳐 이루어집니다.
- 재추론 검증
- 제출된 모델에서 주어진 데이터를 이용하여 결과가 정상 생성되는지 여부를 확인할 수 있도록 재추론합니다.
- 원칙적으로 재추론을 통해 생성된 결과는 참가자가 실제 제출한 결과와 동일해야 합니다.
- 재학습 검증
- 제출된 모델이 허가된 데이터만을 사용하여 학습되었는지, 학습된 모델은 제출된 결과를 재현할 수 있는지의 여부를 재학습을 통해 검증합니다.
- 소스코드 분석
- 소스코드 표절, 미허가 데이터 사용, 모델 조건 불충족 여부 등을 소스코드 분석을 통해 검증합니다.
- 재추론 검증
- 재현성 검증에 문제가 발생하거나 소스코드 표절을 비롯한 규정위반이 확인되는 경우 원칙적으로 해당 결과는 무효처리됩니다.
🧪평가 방법
- 평가 메트릭은 MAE를 사용합니다.
※ 참가자분들에게 제공되는 데이터는 비식별화가 적용되어있지만 평가시에는 비식별화를 복원한 값으로 스코어를 계산하오니 이를 유의하시기 바랍니다.
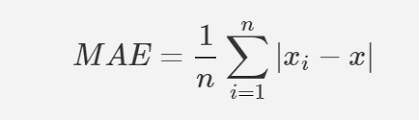
📨문의처
- 인공지능팩토리 ‘제5회 2023 연구개발특구 AI SPARK 챌린지' 內 Q&A 에 접속 후 질문 남겨주시면, 답변드리고 있습니다.