챗GPT 러닝데이의 중급 세션으로 최태균님을 모시고 "Transformer 모델 개요와 GPT3 모델 활용 실습" 세미나를 개최하는데요. 최근 이슈가 된 코알파카를 이용한 실습을 해보려고 합니다. 용어가 생소하신 분들도 계실텐데요. 하나씩 간단히 소개드리겠습니다.

코알파카란? (KoAlpaca)
스탠포드에서 LLAMA 기반 Instruct-following하는 알파카(Alpaca) 모델을 5만 2천개의 데이터셋도 함께 공개했습니다. 이어서 이준범님이 코알파카(KoAlpaca) 이름으로 한국어로 학습된 모델을 아래 깃헙으로 공개했습니다.
https://github.com/Beomi/KoAlpaca
데모를 해볼 수 있도록 텔레그램까지 만드셨네요. (위 깃헙에 들어가시면 접속 링크를 확인할 수 있습니다.)
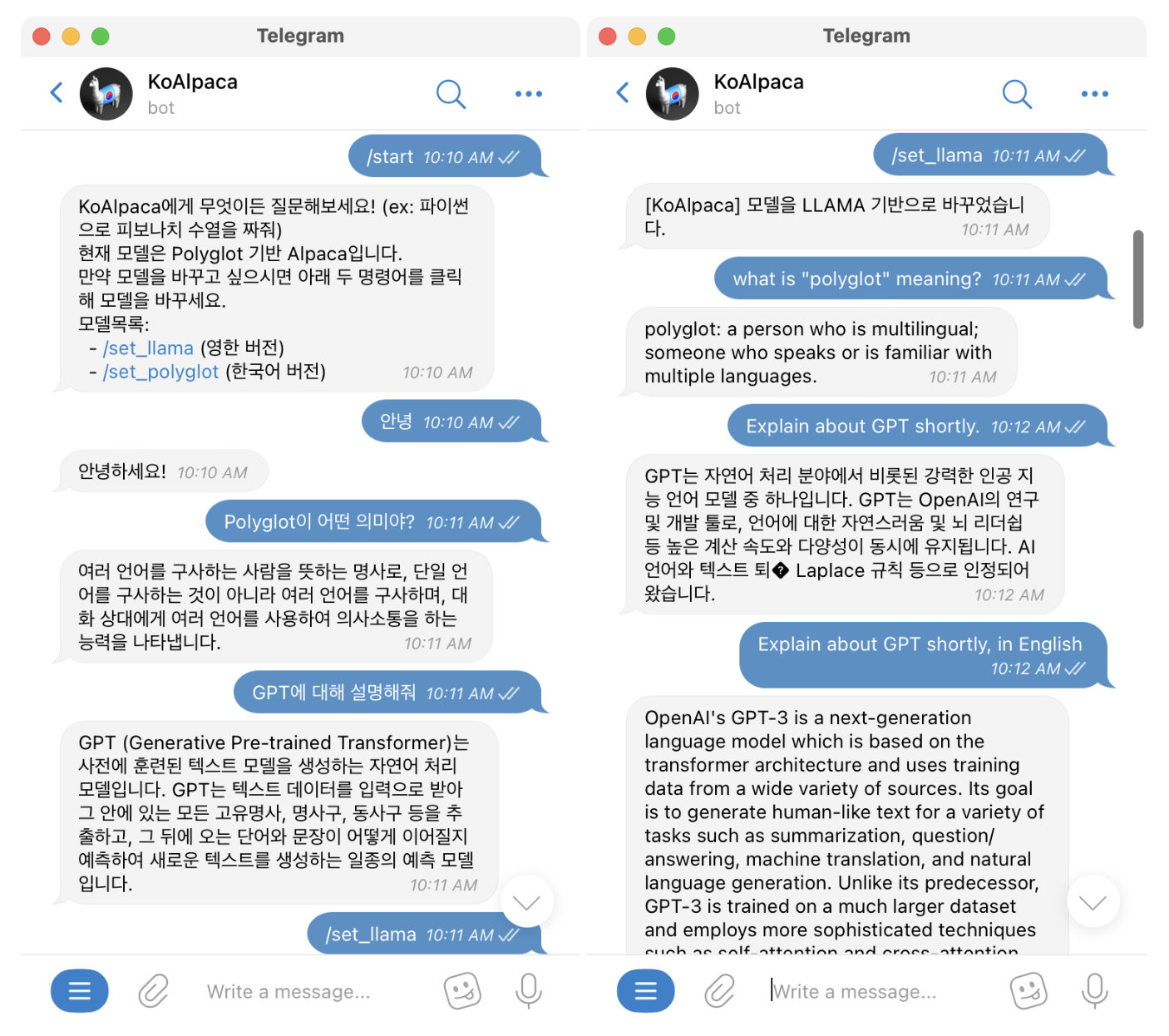
이 모델을 만들기 위해 한국어 데이터셋을 구축을 하셨는데요. 먼저 스탠보드 데이터셋에 instruction과 input 부분만 DeepL API 서비스로 번역하였고, 이를 기반으로 OpenAI ChatGPT API(gpt-3.5-turbo)를 이용하여 output을 생성한 후 데이터셋을 구성했습니다.
인컨텍스트 퓨샷러닝이란?
대규모 언어 모델을 특성 태스크에 적용하기 위해서 여러가지 기법을 사용하는데요. 이번 실습에는 인컨텍스트 퓨샷러닝을 사용할 예정입니다. 인컨텍스트 러닝은 모델 자체는 바꾸지 않고 프롬프트 내의 정보로만 모델을 원하는 태스크를 수행할 수 있도록 학습을 시키는 방법이며, 이 때 모델 가중치는 바뀌지 않습니다. 그리고 퓨샷러닝은 여러개의 샘플을 미리 보여주는 것을 얘기하며, 1개만 보여줄 경우에는 원샷러닝, 하나도 안 보여줄 경우에는 제로샷러닝이라고 합니다.
리뷰 분류?
네이버 영화 리뷰를 분류한 데이터셋이며, 자연어처리 분류 모델에 자주 사용되는 데이터셋입니다. 예전에는 이 데이터셋으로 지도학습 기반의 모델을 만들거나 언어모델을 가지고 와서 파인 튜닝을 했었는데, 이번 실습은 대규모 언어모델을 기반으로 인컨텍스트 퓨샷러닝만으로 태스크를 풀어보고자 합니다.
세미나 참여
- 세미나 상세 안내 >> https://aifactory.space/learning/2300/discussion/193
- 세미나 참여방법 >> 아래 그림처럼 상단 [참여하기] 버튼을 누르시면 됩니다.