
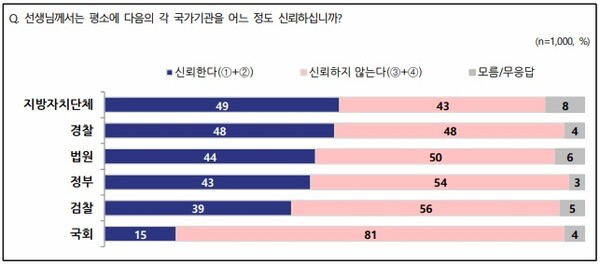
대한민국 국회는 지방자치단체, 경찰, 법원 등을 포함한 국가기관 중 압도적으로 낮은 신뢰도를 기록했다. 답변자의 81%가 국회를 신뢰하지 않는다고 답변하였다. (전국지표조사, 엠브레인퍼블릭·케이스탯리서치·코리아리서치·한국리서치)
안녕하세요! 메페토팀입니다. 😆
저희 팀은 ChatGPT API를 활용하여, 국회의 발의 법률안에 대한 가독성, 정보 접근성을 높이는 웹 서비스를 제안하고 있습니다.
😠 국회의원 월급을 줄여야 해
5명 중 4명은, 국회 신뢰하지 않아
매년 어떤 사회 문제가 대두되면, 이를 해결하지 못하는 국회의원에 대한 불만도 함께 합니다. 이를 반증하듯, 전체 국가 기관 중 국회에 대한 신뢰도는 최하위입니다.
🙋 심의 민주주의, 전자 민주주의란?
정치 신뢰도 지표에서 최상위권을 기록하는 북유럽 국가들 중, 핀란드의 경우 시민발의제를 시행하거나, 의회의 의사 결정과정에 시민들이 참여하는 등 국회와 시민이 긴밀하게 연결된 경우가 많습니다. 하지만, 우리나라의 경우에 시민의 의견 제안 창구는 마련되어 있지만, 건수는 전자 청원 서비스가 시행된 2022년 이후 누적 5,605건으로 10,000명 중 1명에도 미치지 못하는 수치입니다.
😮 이 서비스가 한국에 꼭 필요한 이유
시민의 정책 제안 플로우
문제 인식 → 관련 정책 내용 인식 → 정책 제안 → 제안 결과 확인 → 문제 인식
- 한 사람이 정책을 제안하기까지의 과정을 적어보면, 위와 같은데요. 두 번째 단계인 관련 정책 내용 인식에서부터 큰 어려움이 있다는 것을 알게 되었습니다.

조세특례제한법 일부개정법률안(조해진의원 등 10인), 국회 의안정보시스템
- 법률안 특성상, 명료하게 쓰다보니 가독성이 좋지는 않습니다. 당장 대학생인 저희 팀원들 조차 법률안을 보고 어떤 맥락에서 제안된 법률안인지 파악하기 어렵습니다.
💫 ChatGPT로 국회의사당에 당당하게 입장하기
대형 언어 모델(LLM)인 ChatGPT를 사용하여 정책 제안을 위한 컨텍스트 이해를 돕는다면, 기존 정책 제안 과정에서 병목으로 작용했던 관련 정책 내용 인식을 해소할 수 있습니다.
보여드릴 웹 서비스는 다음과 같습니다.
1. 발의 법률안 검색 & 필터 기능
사용자는 필터 & 검색 기능을 통해 발의자, 발의안명, 소관위원회를 기준으로 발의안을 검색할 수 있습니다.
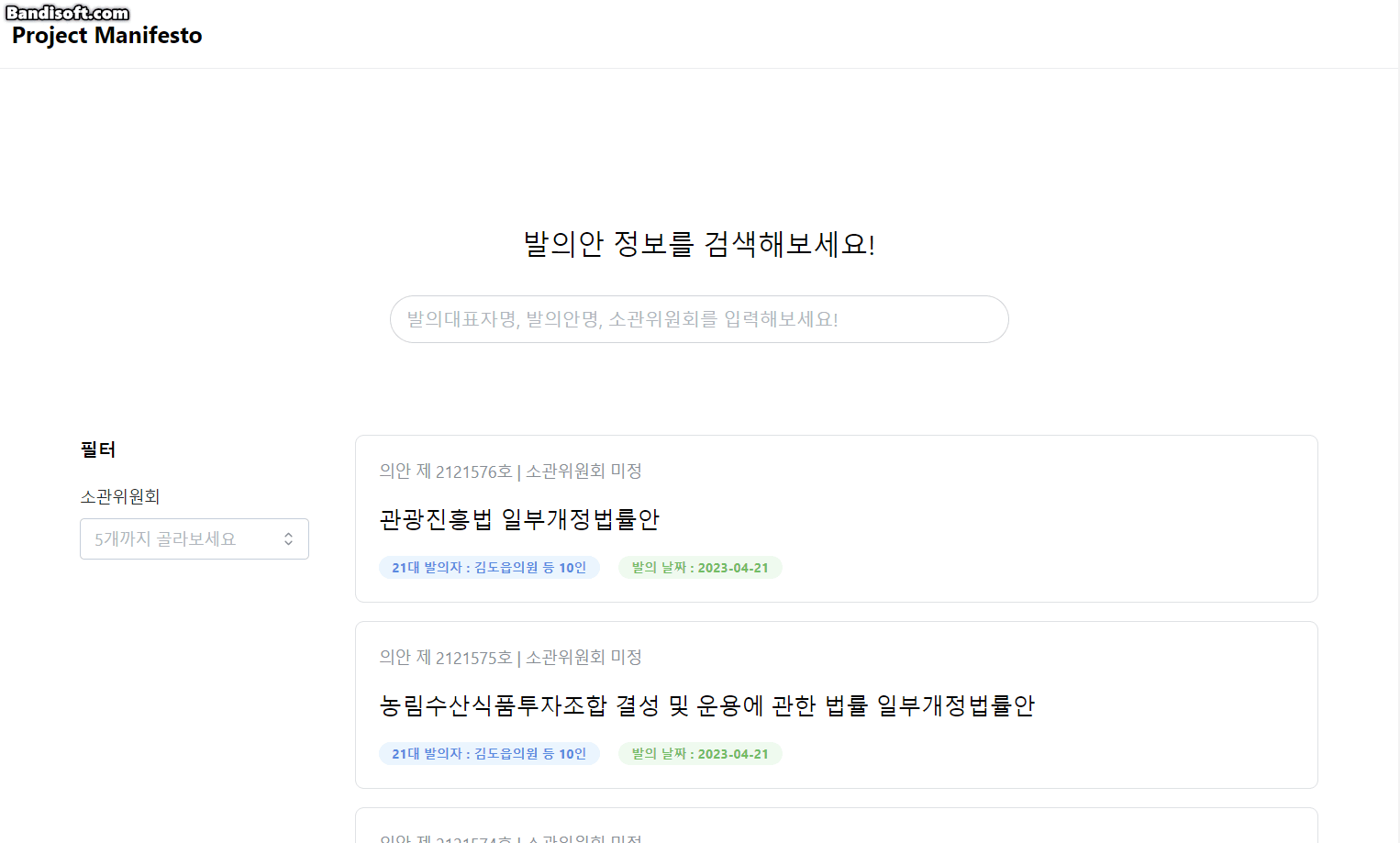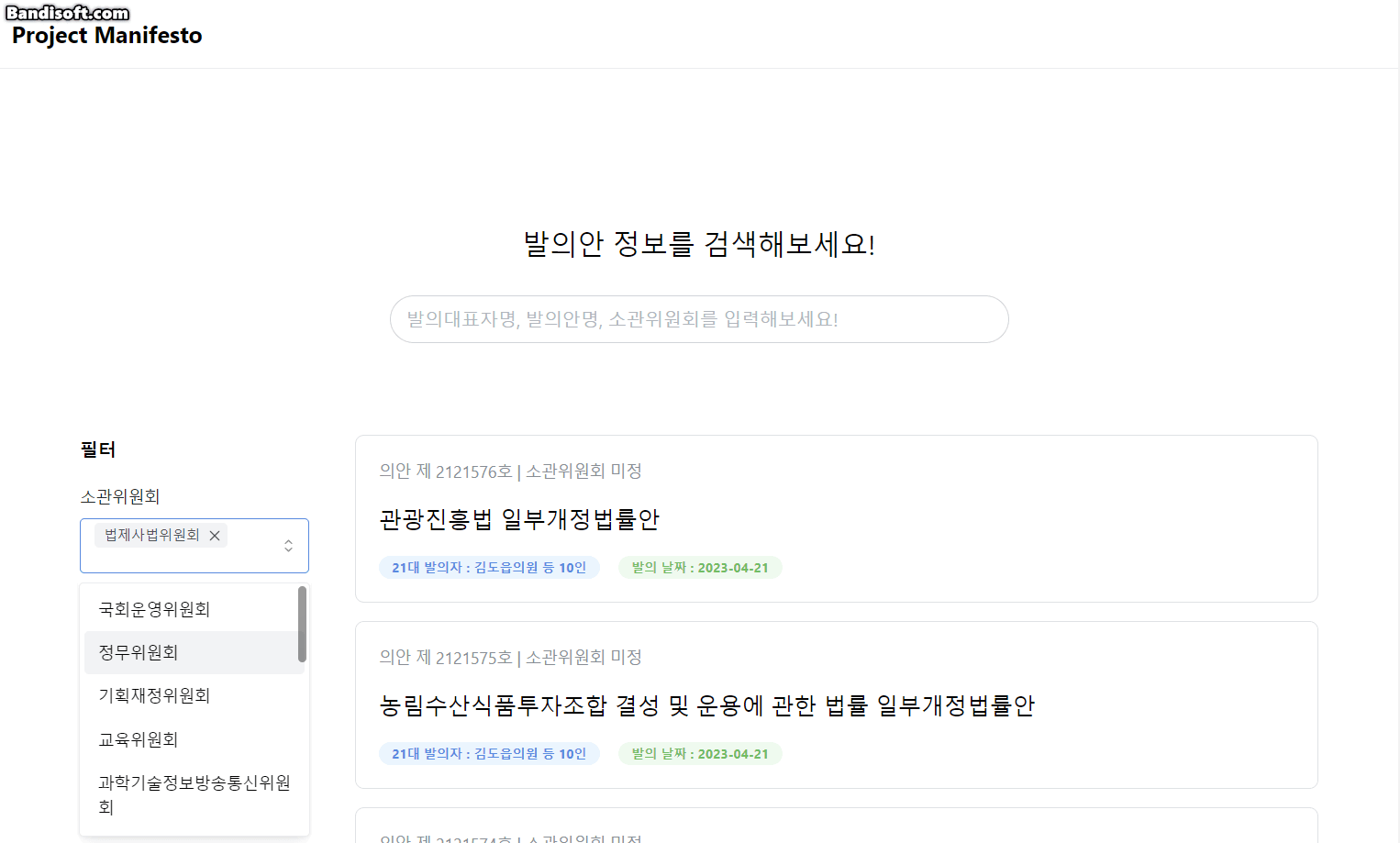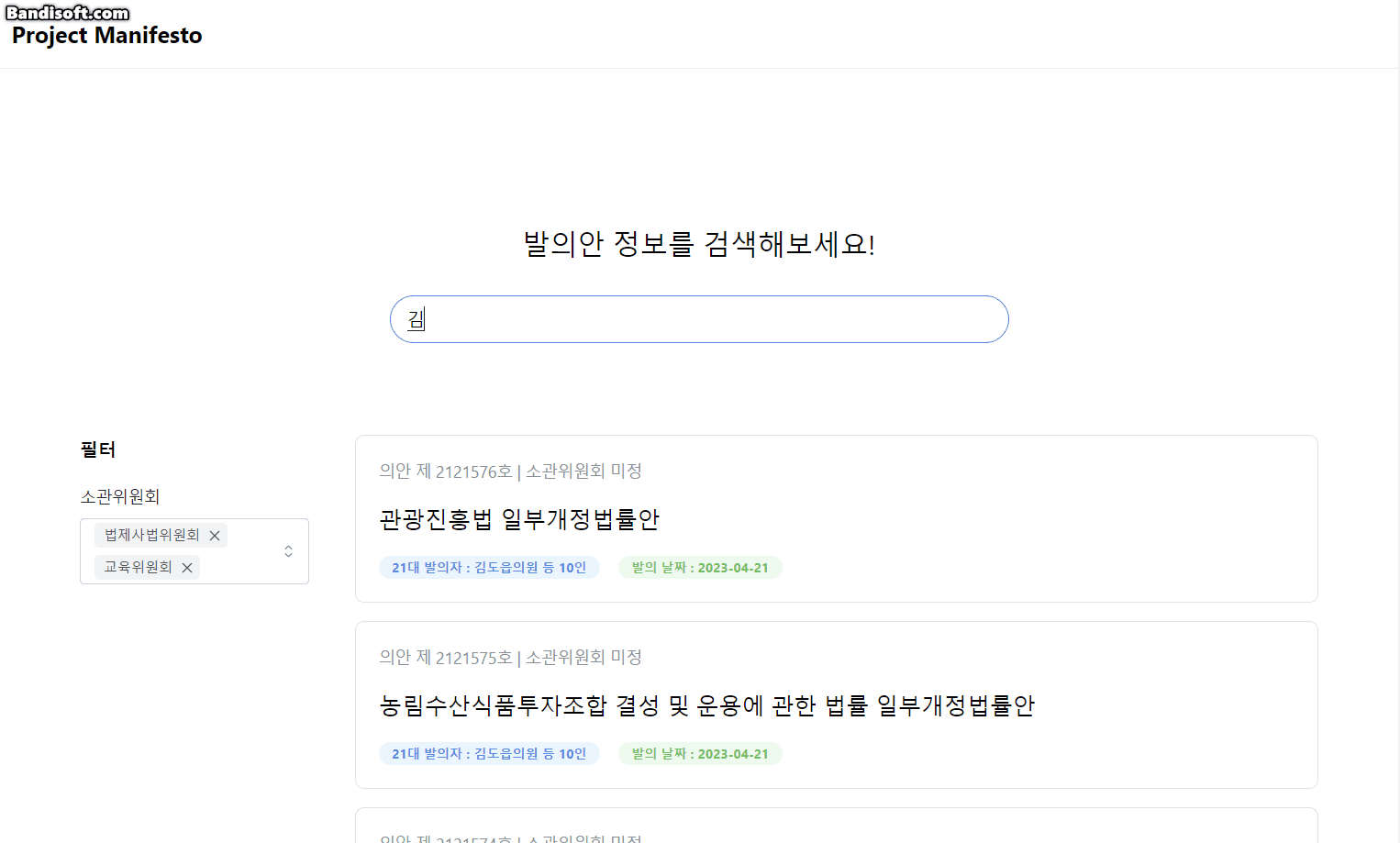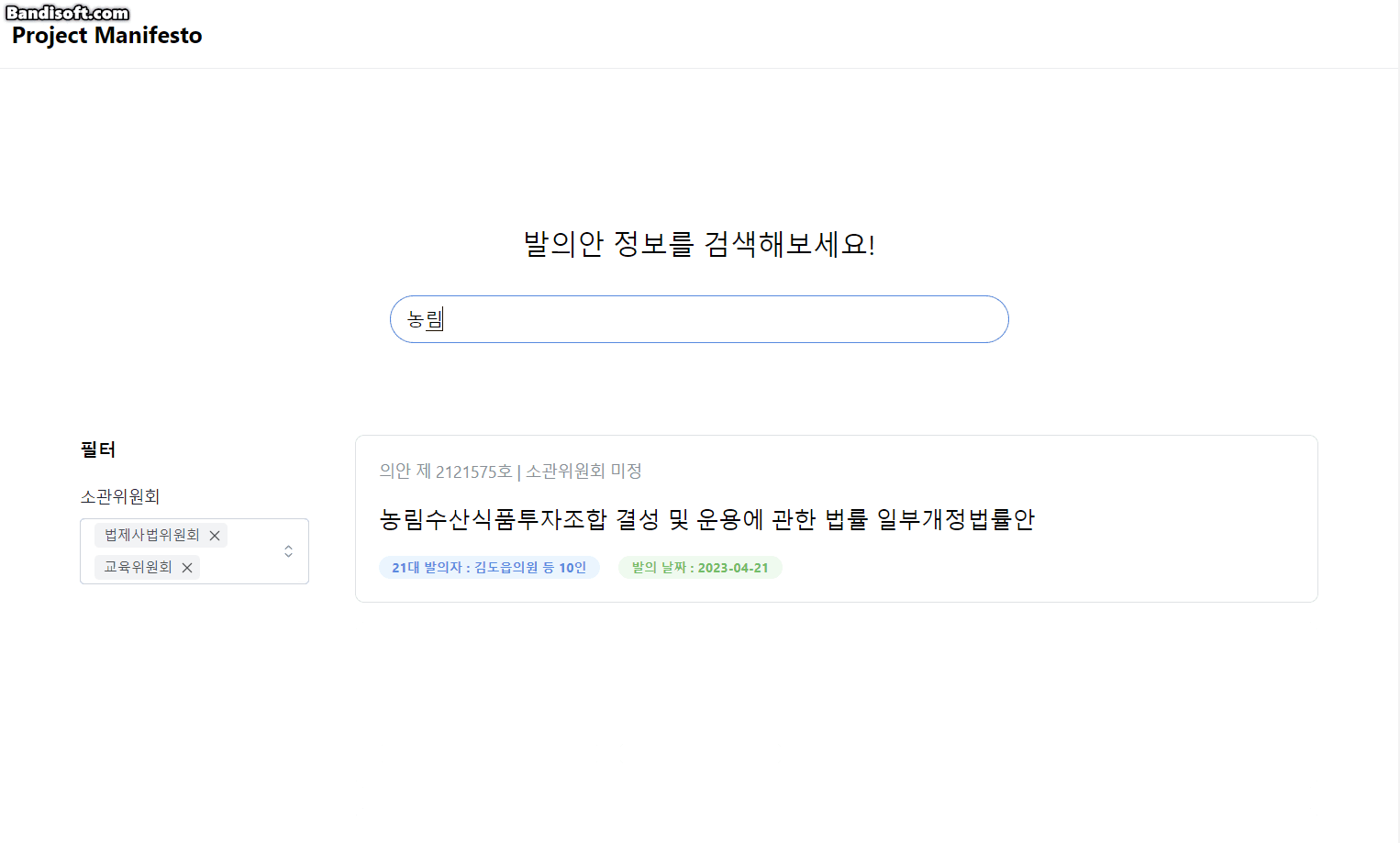
소관위원회란? 국회에서 법안을 상세하게 검토하기 위해 설치되는 작은 단위의 위원회입니다.
2. ChatGPT를 통한 법률안 요약 & 설명
ChatGPT를 통해 기존 법률 발의안 정보를 재구조화 & 부가설명하여 사용자가 이에 대한 이해를 더 쉽게 할 수 있도록 돕습니다.
- AI 제공 단어사전
- ChatGPT가 원문 내용에서 가장 어려운 단어 5개를 선택하고, 이에 대한 설명을 작성합니다.
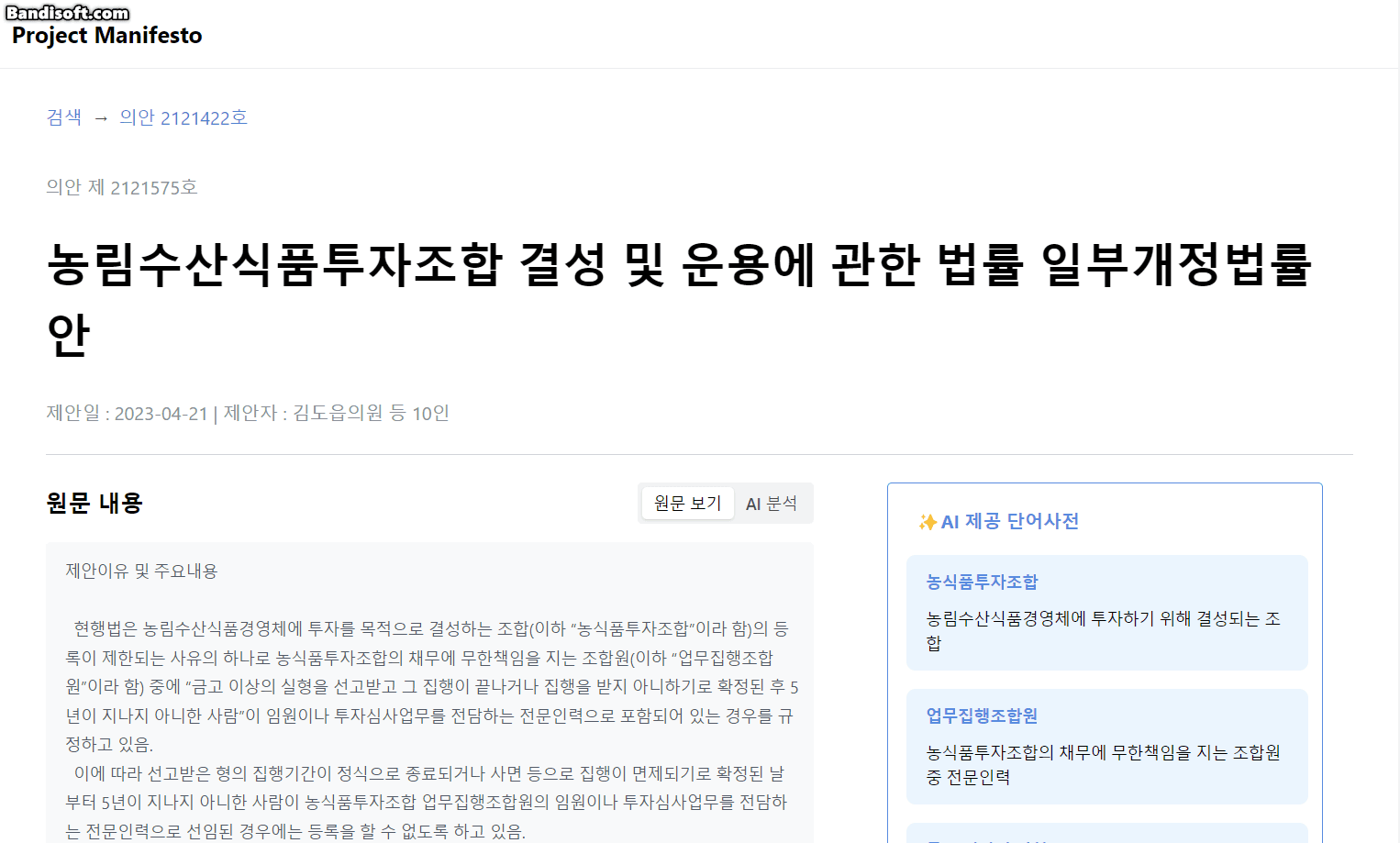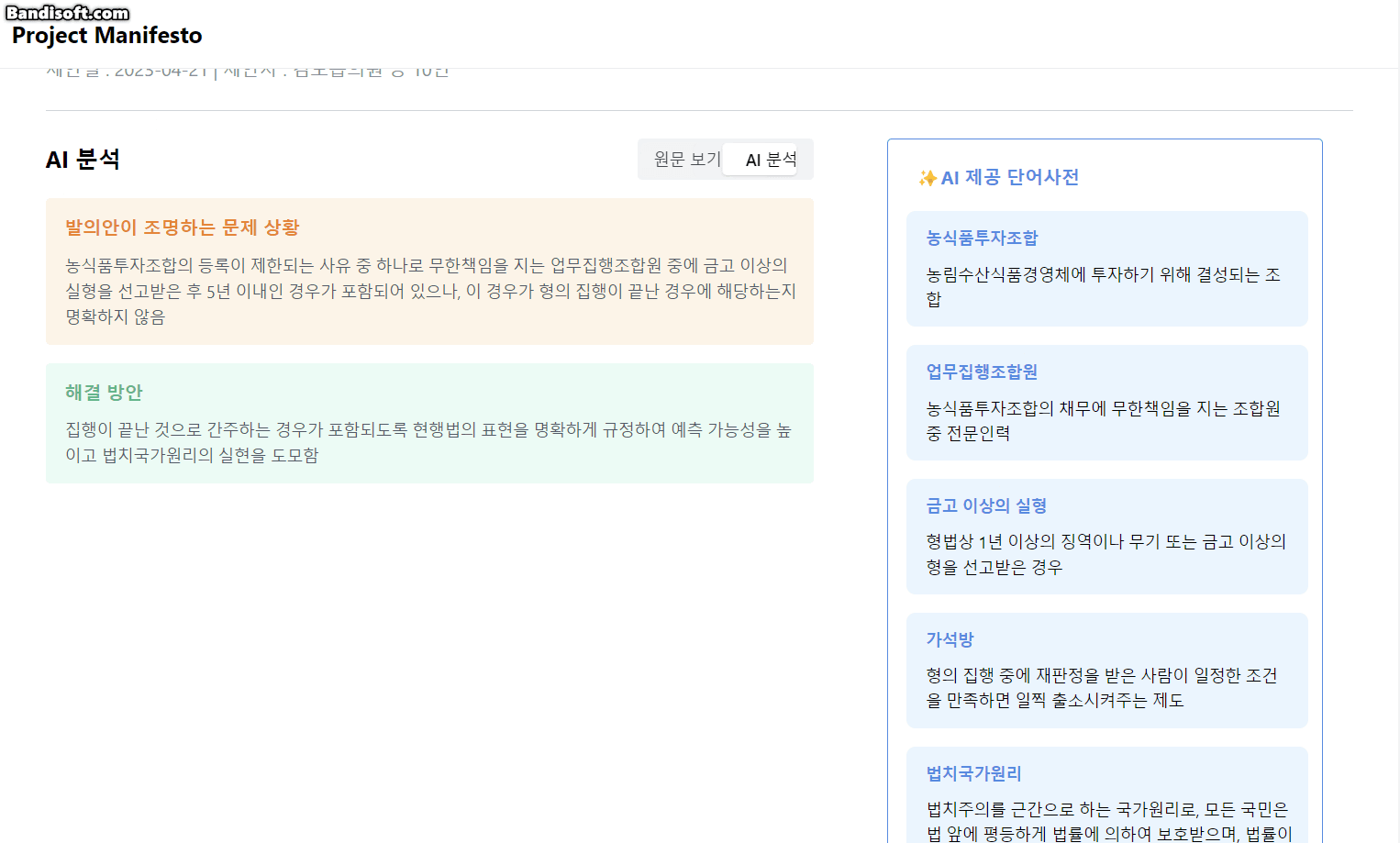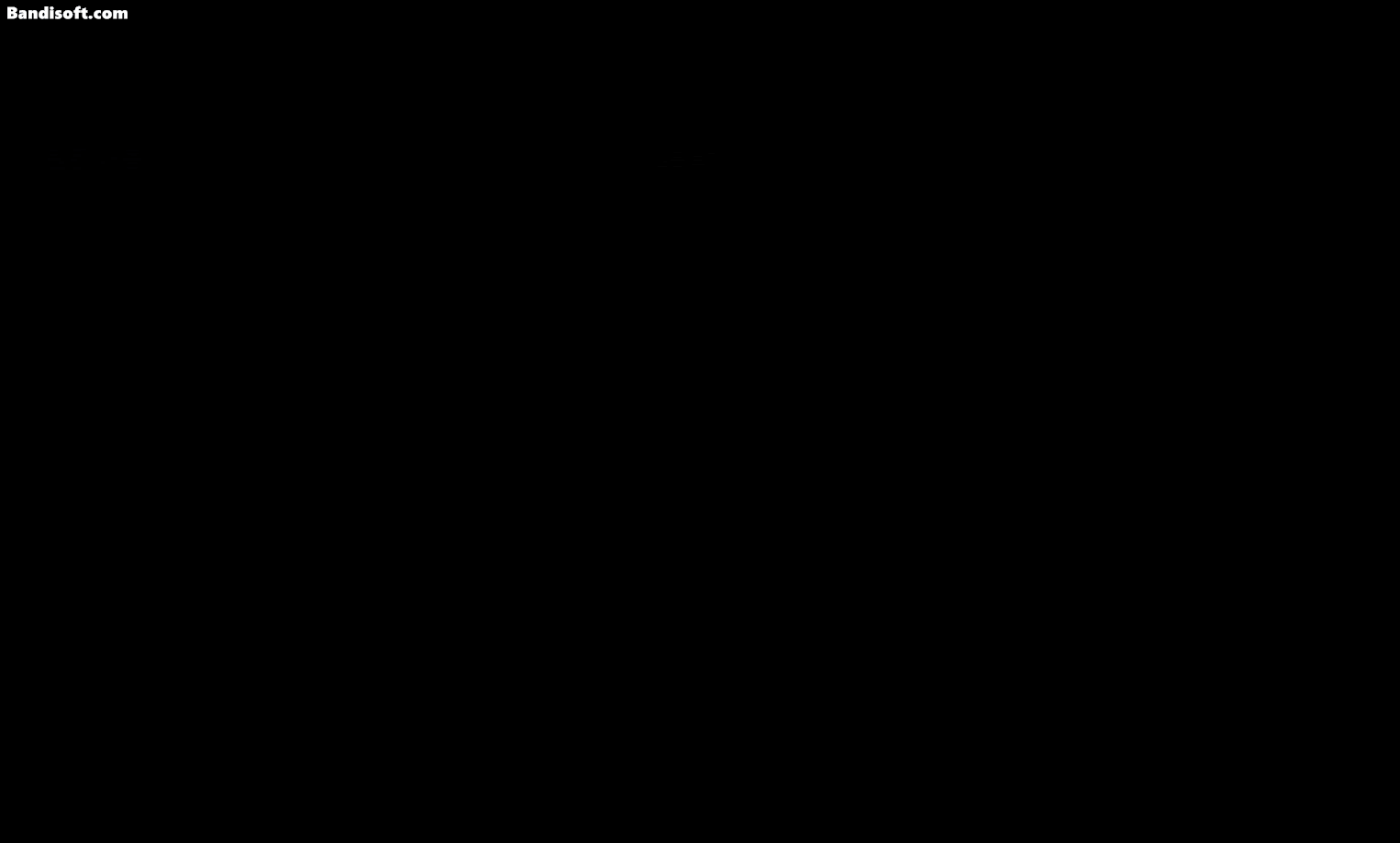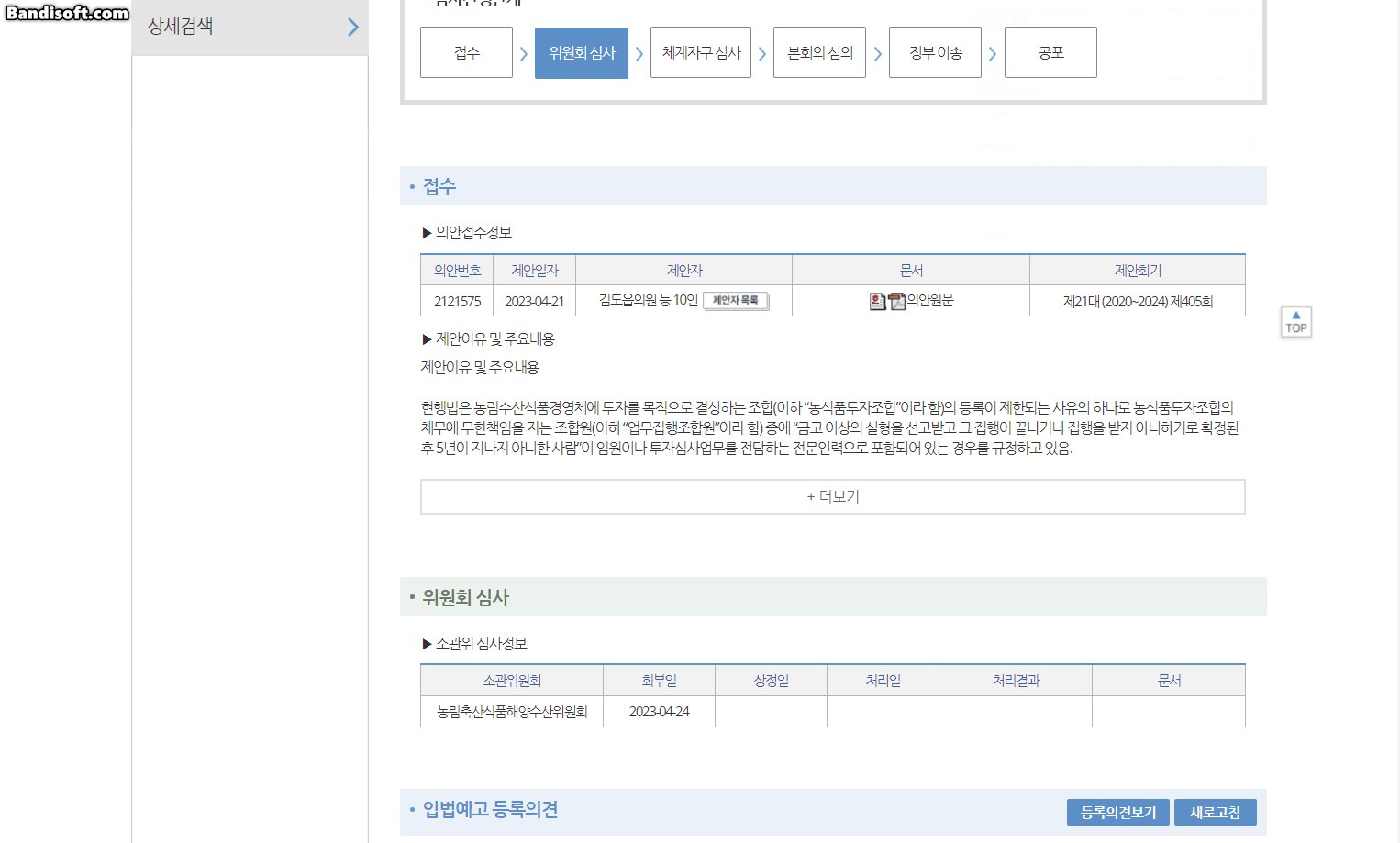
- AI 분석 & 요약
- 법률안이 제안된 문제 상황과, 법률안을 통한 문제 해결 방법으로 발의법률안의 세부 내용을 재구조화하여 보여줍니다.
🧐 GPT 서비스 활용에 관한 자세한 설명
전체적인 GPT 서비스를 활용하여 분석한 발의안 데이터를 데이터베이스에 저장하는 과정은 다음과 같습니다
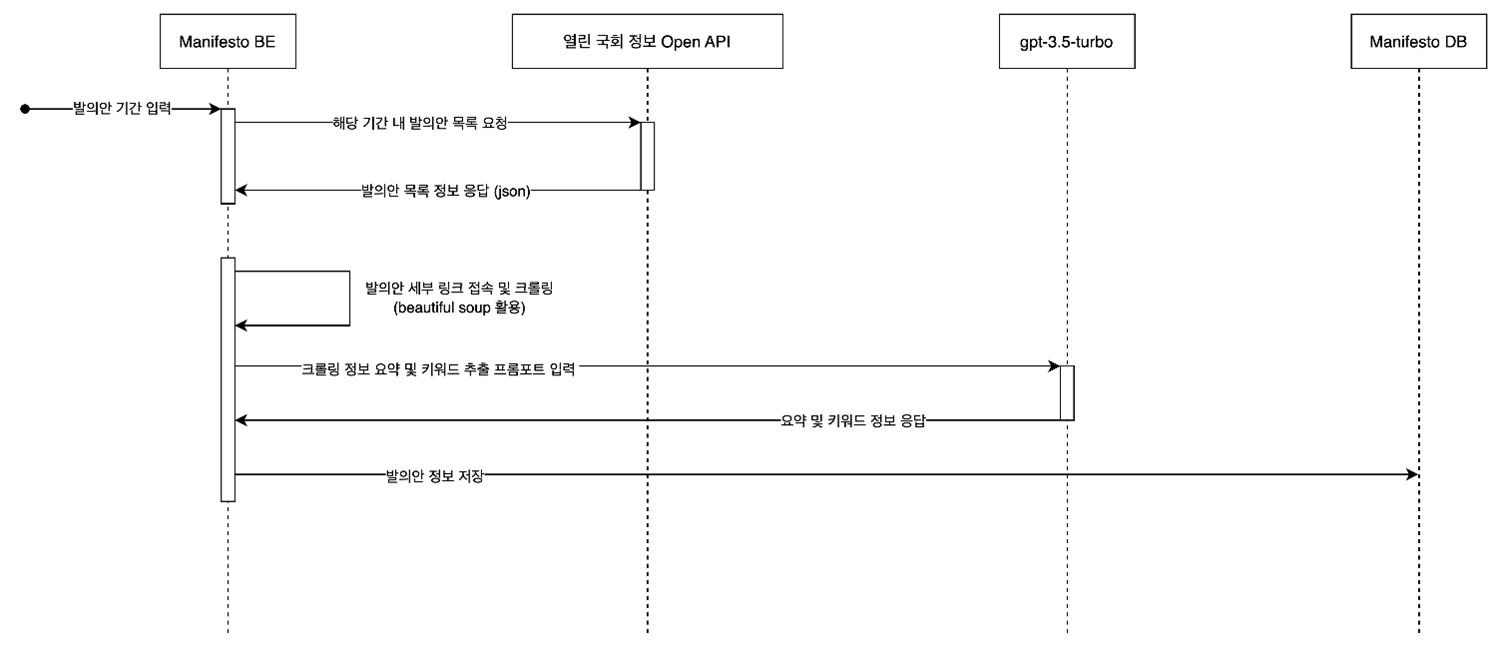
열린 국회 정보에서는 국회의원 발의 법률안에 대한 Open API를 제공합니다. 해당 API의 구조는 다음과 같습니다. 여기서 저희는 “row” 부분을 활용했습니다.
{
"nzmimeepazxkubdpn":[
{
"head":[
{
"list_total_count": 19048
},
{
"RESULT":{
"CODE":"INFO-000",
"MESSAGE":"정상 처리되었습니다."
},
}
]
},
{
"row":[
{
"BILL_ID":"PRC_P2O3N0C3B2Z7Y1Z4H3G9E3D1G4H3G7",
"BILL_NO":"2121190",
"BILL_NAME":"관광진흥법 일부개정법률안",
"COMMITTEE":None,
"PROPOSE_DT":"2023-04-06",
"PROC_RESULT":None,
"AGE":"21",
"DETAIL_LINK":"<http://likms.assembly.go.kr/bill/billDetail.do?billId=PRC_P2O3N0C3B2Z7Y1Z4H3G9E3D1G4H3G7&ageFrom=21&ageTo=21>",
"PROPOSER":"이개호의원 등 10인",
"MEMBER_LIST":"<http://likms.assembly.go.kr/bill/coactorListPopup.do?billId=PRC_P2O3N0C3B2Z7Y1Z4H3G9E3D1G4H3G7>",
"RST_PROPOSER":"이개호",
"PUBL_PROPOSER":"김남국,박광온,서삼석,신정훈,양경숙,어기구,이병훈,조오섭,허영",
"COMMITTEE_ID":None
},
...
}
]
}
위 구조에서는 해당 발의안에 대한 자세한 내용을 제시하지 않고 세부 링크만을 제공합니다. 저희는 해당 링크를 스크랩핑하여 제안 이유 및 주요 내용에 대한 정보를 가져옵니다. 코드는 아래와 같습니다.
# detail link 통해서 컨텐츠 가져오기
def scrape_content(url: string):
# HTML 가져오기
res = requests.get(url)
html = res.content
# soup의 객체 생성
soup = BeautifulSoup(html, 'html.parser')
if soup is None:
return None
# '제안이유 및 주요내용' 부분을 포함하는 div 태그 선택
tag = soup.select_one('div[id="summaryContentDiv"]')
# div 태그 내의 텍스트 출력
return tag.text.strip()
이렇게 가져온 정보를 gpt-3.5-turbo 모델을 이용하여 다음과 같이 프롬포트 입력해서 정보를 JSON 형태로 제공받습니다.
너는 어려운 내용을 쉽게 해설하는 선생님 역할을 해줘. 한국어로 제공된 국회의원 발의법률안의 제안 이유와 주요 내용을 바탕으로 문제 상황, 문제 해결 방안, 그리고 정책이나 법률 관련 어려운 단어 5개를 선별하여 JSON 형태로 응답해야돼. 미사여구는 붙이지마. JSON 구조는 다음과 같아: {"problem": 문제 상황, "solution": 문제 해결 제시 방안, "words":[{"name": 단어 명, "description": 단어 설명}]} 이제 발의법률안의 내용을 제공할 것이야.
def get_ai_analyzed(detail: string):
model = "gpt-3.5-turbo"
messages = [
{"role": "system", "content": 위의 작성된 프롬포트},
{"role": "user", "content": detail}
]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0.5,
max_tokens=800,
)
return response.choices[0].message.content
이렇게 분석된 정보는 아래와 같은 정보를 담고 있습니다. (아래는 테스트 데이터입니다!)
{
"problem": "노동위원회의 심판 기능을 전문적으로 다루는 지방노동법원으로 이관하기 위해 법률 개정이 필요하다.",
"solution": "차별적 처우의 시정신청에 대한 노동위원회의 시정명령 기능을 지방노동법원으로 이관하고, 관련 조사, 심문, 조정, 중재 규정, 시정명령 및 과태료 규정을 삭제한다.",
"words": [
{"name": "지방노동법원", "description": "노동사건을 전문적으로 다루는 법원으로, 지방 법원 내에 설치된다."},
{"name": "노동위원회", "description": "노동 분야의 분쟁 조정 및 노동정책에 관한 자문 역할을 하는 기관이다."},
{"name": "차별적 처우", "description": "근로자에게 부당한 차별을 가하는 행위를 말한다."},
{"name": "시정신청", "description": "부당한 처우를 받은 근로자가 그 처우를 바로잡기 위해 관련 기관에 요청하는 절차이다."},
{"name": "시정명령", "description": "부당한 처우를 시정하도록 명령하는 권한을 가진 기관의 결정이다."}
]
}
위의 분석된 정보와 스크랩핑한 정보를 기존의 API 응답과 결합하여 해당 데이터를 Mongo DB Atlas 에 저장하고 웹페이지에 이를 제공합니다. 전체 코드는 여기를 참고해주세요.
⚡ 기대 효과
- 다양한 전문 용어로 인해 이해하기 어려운 법률안들을 쉽게 해석하여, 국민들의 정치적 참여 효율성을 향상시키는 서비스를 제공합니다.
- 직관적인 사용자 인터페이스와 빠른 검색 기능을 통해, 관심 분야의 입법안을 손쉽게 찾아볼 수 있습니다.
- 인공지능이 지원하는 단어 사전을 활용하여, 정치 관련 용어의 정의를 학습하고 정치에 대한 기본 지식을 향상시킬 수 있습니다.
메니페스토 프로젝트는 누구나 쉽게 이해하고 학습할 수 있는 정치 지식을 제공하고, 더 큰 참여를 도모하여 국민 모두가 진정한 주인공이 되는 정치를 만들어갑니다. 👊
📬 Contact
- 팀명: 메페토
- 팀장: 황인선 (inseon_ug@gm.gist.ac.kr)
- 팀원: 서동호 (ehcws333@gm.gist.ac.kr)
- 팀원: 박현 (andrew6303@gm.gist.ac.kr)
- 팀원: 우성윤 (woosy2207@gm.gist.ac.kr)
- 코드 : mefeto Github Repository