
개요
최근 위성영상을 이용한 AI 모델 개발에 대한 관심이 늘어나고 있습니다. 본 대회에서는 제주시의 위성이미지를 사용하여 토지의 피복을 5가지(4가지 + 비대상지) 클래스로 분류하는 Semantic Segmentation 모델을 개발합니다. 위성이미지는 우리가 흔히 접하는 8-bit RGB 이미지와는 조금 다르기 때문에 좀 더 도전적인 문제입니다.
Semantic Segmentation
의미론적 분할(Semantic Segmentation)은 이미지가 주어졌을때 이미지의 각 픽셀이 어느 클래스인지 분류하는 문제입니다. CNN으로 H x W x 3 크기의 이미지 내의 객체를 C개의 클래스로 분류한다고 가정해 봅시다. CNN은 H x W x C 크기의 이미지를 input으로 받아 H' x W' x K 크기의 feature map으로 encoding 합니다. 이 feature map을 H x W x K 크기로 up-sampling하고 최종적으로 H x W x C 크기의 출력을 내놓습니다. 각 픽셀은 1 x 1 x C 크기의 벡터로 해당 픽셀이 각 클래스일 확률을 나타냅니다. 보통 가장 높은 확률을 가지는 클래스로 픽셀을 분류하여 최종 결정을 내립니다.
데이터
대회에 사용되는 데이터는 AI Hub에서 제공하는 ‘토지 피복지도 항공위성 이미지 데이터(제주도)’입니다. 이 데이터는 제주지역 국토의 환경변화를 탐지하거나 토지 이용 현황을 효율적으로 탐지하기 위한 토지 피복 분할이나 변화탐지 AI 모델개발에 사용될 목적으로 구축되었습니다. 본 대회에서는 512 x 512 위성영상 데이터 만을 사용합니다.
학습용 데이터는 tif 형식의 이미지와 마스크로 구성됩니다. AIHub에서 데이터를 다운받으면 Training과 Validation으로 데이터가 나뉘어져 있습니다. 학습은 Training에 있는 TS_위성영상_FGT_512픽셀.zip을 사용하고 테스트는 Validation의 VS_위성영상_FGT_512픽셀.zip을 사용합니다. 학습용 데이터는 총 800장, 테스트 데이터는 총 100장입니다.
이미지는 512 x 512, 4-channel, 8-bit uint 입니다. 본래 위성에서 얻는 이미지는 일반 RGB 이미지보다 훨씬 많은 정보를 포함하고 있습니다. Bit-depth도 더 크고 channel 수도 훨씬 많습니다. 본 대회에서 사용하는 데이터는 8bit, 4-channel의 이미지로 RGB와 NIR(적외선) channel로 구성되어 있습니다. 모델 학습 시에는 4-channel의 정보를 모두 사용할 수도 있고 RGB-channel의 정보만 사용할 수도 있습니다.
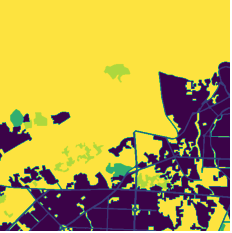
마스크는 각 픽셀이 어느 클래스에 속하는지를 담고있는 1-channel의 흑백 이미지입니다. 각 픽셀은 10(건물), 30(도로), 70(산림), 90(농경지), 100(비대상지) 중 하나의 값을 갖습니다.
(좌) 위성이미지 (우) 마스크

평가 지표
Segmentation에서 범용적으로 사용되는 mIoU(Mean Intersection of Union)를 사용합니다.
IoU는 객체 인식, 분할 등에서 성능평가에 사용되는 지표로 ‘검출한 영역과 실제 영역이 얼마나 겹쳐있는가?’를 수치화한 것으로 생각할 수 있습니다. 수학적으로 IoU는 다음과 같이 계산합니다.
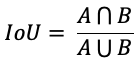
IoU는 0에서 1사이의 값을 가지게 됩니다. IoU가 0이면 겹쳐진 영역이 없다는 의미로 예측이 완전히 틀렸다는 것이고, 1이면 두 영역이 완전히 겹쳐졌다는 의미로 예측이 정확하다는 것입니다. Semantic Segmentation에서는 각 클래스 별로 IoU 값이 나오게 되고 이 값들의 평균값(mIoU)를 성능평가 지표로 사용합니다. 본 대회에서는 이 mIoU를 성능평가 지표로 사용합니다.