
대회 개요
배경
최근의 인공지능은 MNIST, CIFAR-100, ImageNet 등 Image Classification (이미지 분류) 문제의 대표적인 벤치마크에서 90% 이상의 정확도를 달성하며 super-human 수준에 도달했다고 평가받고 있다.
하지만 이러한 성공적인 모델들을 막상 실세계의 문제를 해결하려고 적용할 때는 다양한 문제가 발생하는데, 본 대회는 그 중에서 파괴적 망각 문제를 해결하고 연속학습을 달성하는 것을 목표로 한다.
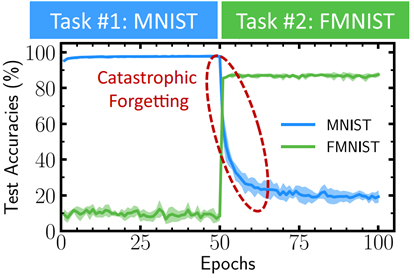
Catastrophic Forgetting (파괴적 망각)
파괴적 망각 문제는 학습하려는 모델에 연속적인 방식으로 입력 데이터를 학습하려고 할 때 발생하며, 근본적으로 모델 가중치의 덮어쓰기에 의해 발생된다고 설명할 수 있다.
예를 들어, 현존하는 모든 차량의 외관 데이터를 학습한 모델은 지금까지 학습한 차종을 잘 분류할 수 있다.
하지만 시간이 지나 신차가 여럿 출시되고 새로운 차종에 대한 분류를 위해 이 모델을 업데이트 해야한다고 가정해보자.
- 이전에 학습에 사용했던 모든 차량의 외관 데이터와 신차에 대한 외관 데이터를 모두 모아 새 모델에 처음부터 새롭게 학습하는 것은 비용이 너무 많이 들고, 신차가 추가될 때마다 매번 새로 학습해야 하는데 그 비용은 점점 증가하는 문제가 있다.
- 이전에 학습된 모델에 신차에 대한 외관 데이터만을 연속적으로 학습시키면 파괴적 망각이 발생한다.
→ 신차에 대한 학습이 추가적으로 이루어짐으로써 이전에 학습한 차량과 신차 모두 잘 분류하기를 기대했겠지만,
→ 실제로는 이전에 학습했던 지식은 거의 잃어버려 방금 학습한 신차에 대해서는 분류를 잘 수행하더라도 이전에 학습했던 차종을 더이상 분류하지 못하는 결과를 얻게 된다.
→ 신차 데이터에 의해 이전에 학습된 모델의 가중치가 덮어써지며 이전 차종에 대한 의미를 잃어버리게 된 것이다.
Continual Learning (연속학습)
연속학습은 파괴적 망각 문제를 해결하여 이전 task와 현재 task 모두에서 좋은 성능을 내는 것을 목표로 한다.
연속학습 실험의 전제조건은 다음과 같다.
- Disjoint set으로 이루어진 여러 task들을 연속적인 방식으로 학습한다.
- 다음 task를 학습하기 시작하면 더이상 이전 task 데이터에 접근할 수 없다.
- 지금까지 학습한 모든 task 데이터에 대해 평가를 진행한다.
예를 들어,
Task 0: {(X,Y) of class 0, 1, …, 9}
Task 1: {(X,Y) of class 10, 11, …, 19}
…
Task 9: {(X,Y) of class 90, 91, …, 99}
학습 데이터가 위와 같이 구성되어 있다면,
Task 0 학습, task 1 학습, …, task 9 학습 과 같이 연속적으로 학습이 진행되고,
만약 task 2를 학습 중이라면 이전 task에 해당하는 task 0, task 1 데이터는 더이상 사용할 수 없다.
(물론 현 시점에서 아직 발생하지 않은 future task (task 3, …) 데이터를 미리 학습해서도 안된다.)
Task 9 까지 학습이 모두 완료되면, 지금까지 학습한 class 0~99 중 어떤 입력에 대해서도 올바른 분류를 수행할 수 있어야한다.
평가방법
학습한 모든 task 입력에 대해 top-1 accuracy(%)를 사용
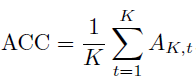
K: 전체 task 개수 (ex. 10)
A_K,t: task K 까지 학습 후 (모두 학습 완료 후), task t 데이터에 대한 top-1 accuracy
데이터셋 정보
차량 외관 영상 데이터 (AI-Hub 제공: https://www.aihub.or.kr/aihubdata/data/view.do?dataSetSn=554)
차종 100종에 대한 차량 외관 학습데이터 322,664 장
→ 소분류ID(1~100)를 class label(0~99)로 활용
Trainset
10개 task로 분할한 차종 100종에 대한 차량 외관 학습데이터 290,004 장
source: 091.차량 외관 영상 데이터/01.데이터/1.Training/원천데이터/TS*.zip
Task 0: {(X,Y) of class 0, 1, …, 9}
Task 1: {(X,Y) of class 10, 11, …, 19}
…
Task 9: {(X,Y) of class 90, 91, …, 99}
Testset
차종 100종에 대한 차량 외관 학습 데이터 32,660 장 (random order)
source: 091.차량 외관 영상 데이터/01.데이터/2.Validation/원천데이터/VS*.zip
https://drive.google.com/file/d/1lNlg8xgSwR8ip9NJWkbh8E5dQEZx3uDj/view?usp=sharing
샘플 데이터 및 제출 csv 형식은 '데이터' 탭 하단 ‘기타 파일’ 참조
| X (input) | Y (label) | |
|---|---|---|
| 형식 | jpg image (1920x1080x3) | int (0~99) |
| 예시 |  | 6 |
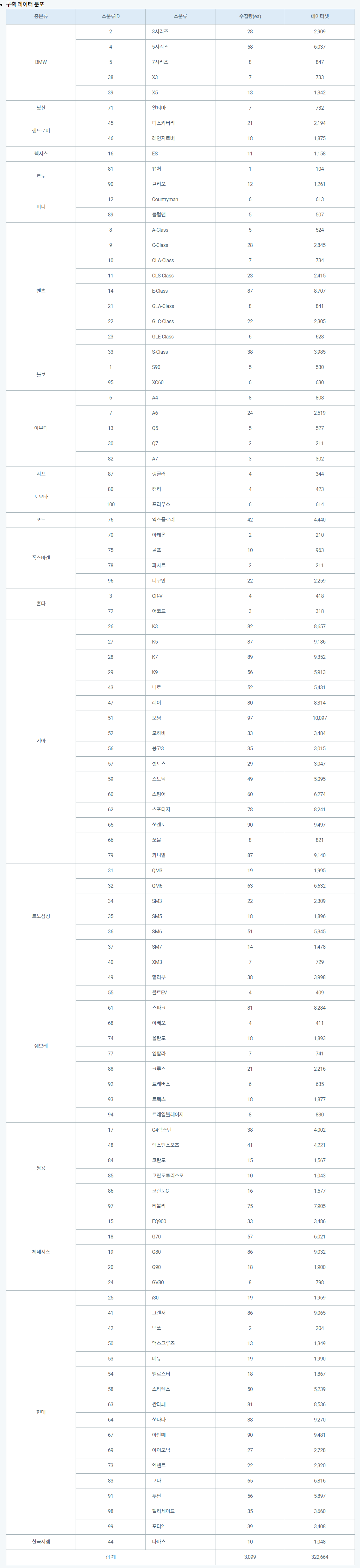
데이터 분포
서비스 활용 시나리오
- 자율 주행 차량을 위한 전용 모델
- 도로 주행하는 승용차량 차종 구분을 위한 전용 프로그램에 활용
- 자율 주행 차량에 연계된 도로 위 사물 인식 시스템의 한 모듈로서 포함됨
- CCTV 연동 전용 모델
- 도로를 주행하는 승용차량 차종 구분을 위한 전용 프로그램에 활용
- 자동차 주행 도로에 설치된 CCTV와 연계된 도로 위 사물 인식 시스템의 한 모듈로서 포함된
- 자동차 견적 및 수리 App 구성 모듈
- 자동차 사용자가 직접 촬영한 자동차 사진에서 차종 및 외관 구성 요소를 구분해내고, 각 구성 요소별 이상 탐지를 하는 별도의 모듈과 연계하여 견적 또는 소리에 대한 정량적 지표 출력 가능