
1.배경
- 최근 세계적으로 한국문화에 대한 관심도가 늘어나며 한식에 대한 관심또한 커지고 있습니다.
- 한식은 메인요리 외에도 다양한 반찬과 같이 곁들여 먹는게 일반적인데 한식을 잘 모르는 외국인 기준에서 먹는 음식이 어떤 음식인지도 모르고 먹는 경우가 많습니다.
- 한식을 잘 모르는 사람들에게 한식을 더욱 알리고 친숙해지도록 한식 분류 모델 챌린지를 제안합니다.
- 한식은 같은 음식이라 하더라도 지방, 지역에 따라 음식 재료의 구성이 약간씩 달라지기도 하며 조리방법 또한 달라지기도 합니다. 따라서 이런 모든 경우를 고려한 학습은 어렵기 때문에 한정된 레이블을 사용하는 few-shot learning classification 챌린지를 진행합니다.
2. few-shot learning
- few-shot learning이란 각 클래스당 1~10개 정도의 학습데이터만을 사용해서 학습하는 방법을 의미합니다.
- 매우 적은 학습데이터셋으로 학습해야 하는 조건이 매우 어려운 만큼 이러한 문제를 풀기 위해 많은 방법들이 소개되었는데, 그중에서도 transfer-learning을 기반으로 이번 챌린지를 진행합니다.
- 먼저 transfer-learning에 대해 간략히 소개를 하자면, 거대한 학습 데이터셋에 사전 학습된 모델의 가중치를 사용해 한정된 레이블(few-shot)을 사용해서 재학습하는 과정을 말합니다.
- 최근 few-shot learning에서 준수한 성능을 보이는 방법은 주로 사전학습시 거대한 학습 데이터셋에 self-superviesd방법을 적용시켜 사전학습시키는 방법입니다.
3. 데이터 제공
- 데이터셋은 AI-Hub에 공개된 한국 이미지(음식) 데이터셋을 활용합니다.
- 데이터셋 출처 : https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=116&topMenu=100&aihubDataSe=ty&dataSetSn=79
- 보다 쉬운 챌린지를 위해 총 12개의 대분류 밑에 150개의 소분류로 나눠져 있지만, 12개의 대분류를 분류하는 문제로 정의합니다.
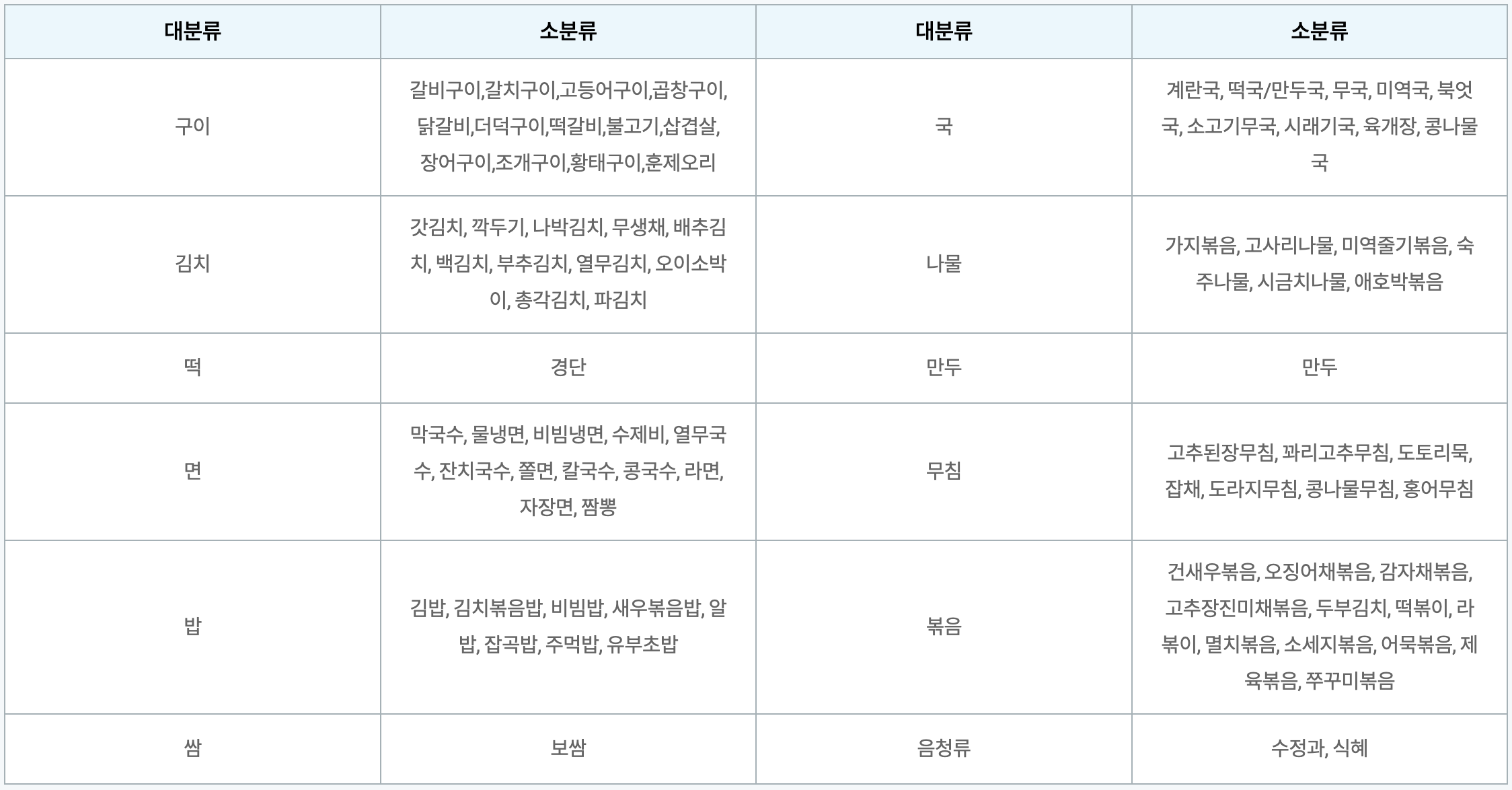
- 학습 데이터셋은 12개의 대분류당 10개의 데이터가 주어져 총 120개의 학습데이터셋으로 구성됩니다.
- 테스트 데이터셋은 12개의 대분류당 100개의 데이터가 주어져 총 1200개의 테스트데이터셋으로 구성됩니다.
4. 평가방법
- 이미지 분류에 사용되는 Top 1 acc (%)를 평가방법으로 사용합니다. ( Top 5 acc는 평가하지 않습니다.)
5. 대회규칙
- 외부 데이터셋은 자유롭게 사용가능합니다.
- 초거대 model의 pre-trained weight를 사용하는것또한 가능합니다.