
1. 주최
경희대학교 AI실전프로젝트 - SUN TEH JEN
2. 개요
최근 인터넷 상에서 수많은 악성 댓글들이 생성되고있습니다. 이는 사회적 이슈, 욕설, 윤리 등에 문제가 되는 다양한 단어 및 문장들이 나오고있습니다.
특히 유튜브, 기사, SNS 등의 댓글에서 악성 댓글로 인해 누구나 살면서 할 번쯤 피해를 볼 가능성이 높습니다. 실제로 악성댓글로 인한 많은 피해 및 사고가 발생하기도 합니다.
따라서 본 대회에서는 악성 댓글을 탐지 및 판별하는 정확도가 높은 인공지능을 목표로하고자합니다.
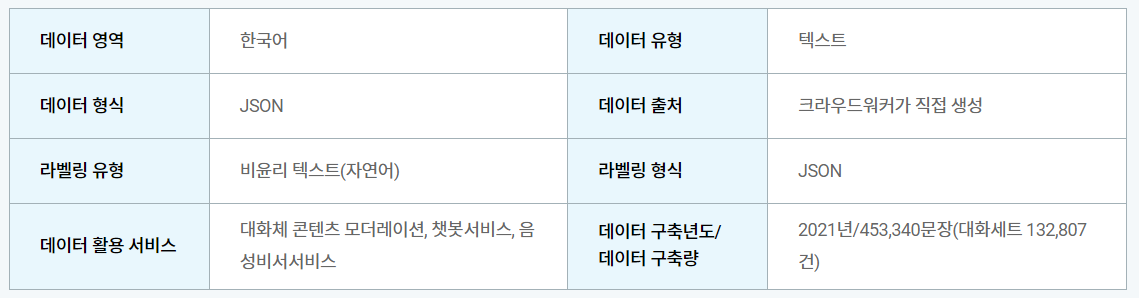
3. 데이터 개요
총 453,340문장 / 대화세트 132,807의 비속어, 비윤리 텍스트.
각 5가지 상황에 따른 다양한 비속어, 비윤리 문장으로 이루어진 Json 데이터셋이 있습니다.
각 Json 파일은 Text파일 형식인 원천데이터과 함께 있습니다.
4. 결과
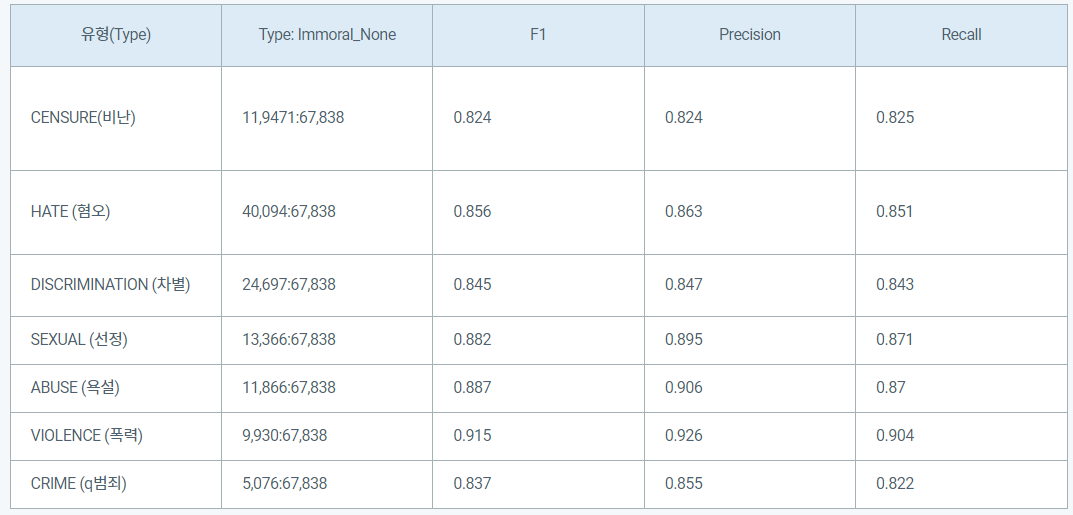
제공된 데이터 셋에서 각 각의 언어의 비윤리 속성 및 정확도가 존재합니다. 각 각의 Precision(정밀도) 측정 후, 이를 평균화한 값이 최종적인 결과 및 평가방법으로 결정합니다.
5. 평가 방법
모델을 통해 도출된 윤리 단어의 정확도에 대한 결과값을 파일로 저장하여 제출합니다.
최소 결과값이 0.5 이상이어야하며 최대 값은 1입니다.