
이미지 분류를 위한 딥러닝 문제해결 패턴 리뷰
- 강의 링크
- AIFactory 에서 제공하는 세미나 중에서 흥미로웠던 부분을 중심으로 리뷰했습니다.
- 실제로 많은 도움이 되었고 전체적인 진행방향을 잡기 좋은 강의였습니다.
1. 탐색적 데이터 분석
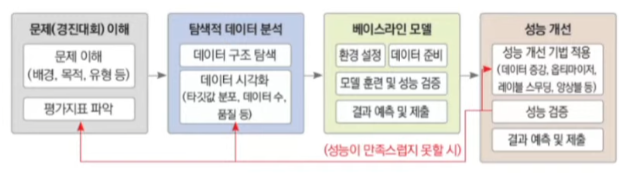
- 1단계 : 문제(경진대회) 이해
- 문제를 정확히 이해해야 목표점을 명확히 설정할 수 있음
- 2단계 : 탐색적 데이터 분석(EDA)
- 주어진 데이터를 면밀히 분석
- 딥러닝 성능은 데이터 수와 품질에 크게 좌우됨
이미지 분류 딥러닝에서는 선택적 데이터 분석의 양이 적음, EDA 양이 적음
- 3단계 : 베이스라인 모델 설계
- 딥러닝 프레임워크를 활용해 기본 모델 만들기
- 처음부터 좋을수는 없음
tensorflow는 배포가 pytorch 보다는 편함
- 4단계 : 성능 개선
- 베이스라인 모델을 점진적으로 개선
- 무언가 놓친 것 같다면 1단계나 2단계로 돌아가는 것도 바람직
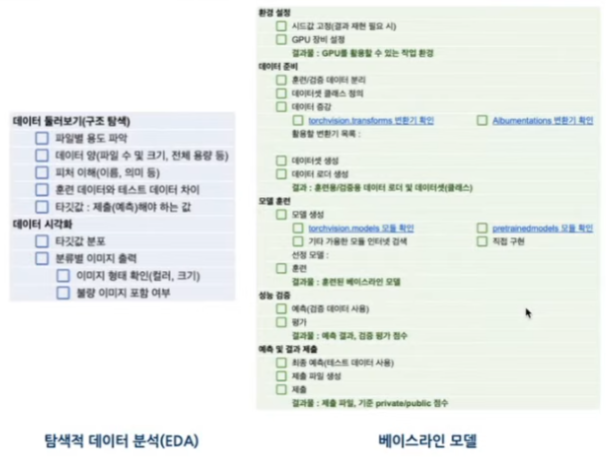
딥러닝 문제해결 체크리스트

- 이미지 부분에서는 EDA 할게 별로 없음
- 이진 분류 문제의 타깃값 분포 확인 & 다중 분류 문제의 타깃값 분포 확인
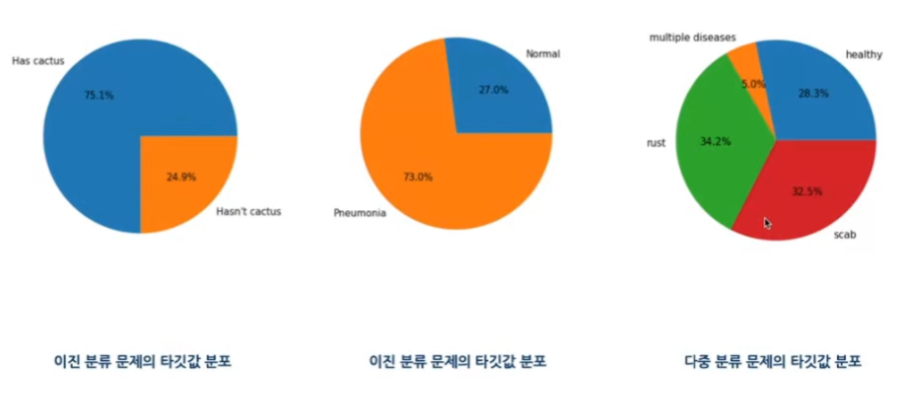
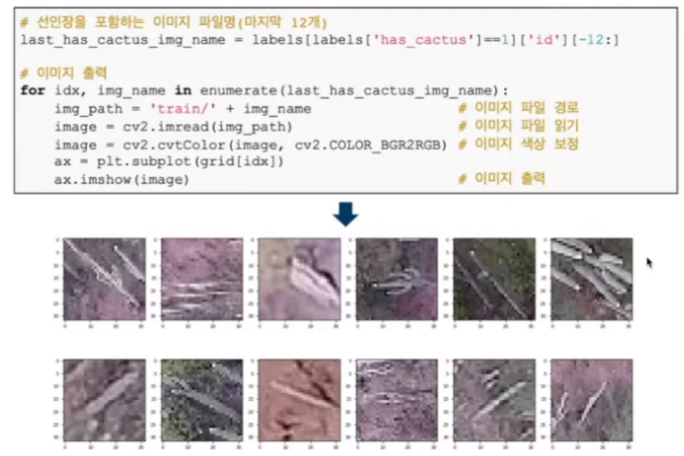
- 실제 이미지 출력 및 확인
- 시각화를 통해 클래스별 차이를 눈으로 확인
- 이진 분류 문제의 타깃값 분포 확인 & 다중 분류 문제의 타깃값 분포 확인

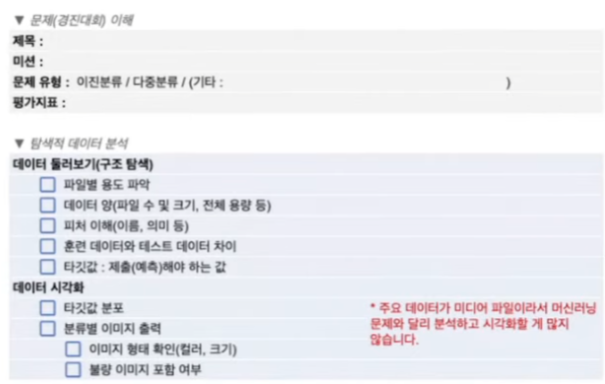
- 딥러닝 이미지 분류 체크리스트
2. 베이스라인 모델 설계

- 베이스라인 모델은 딥러닝 모델링의 시작점
- 시작부터 최고 성능의 모델을 시도해도 성공 하기 어려움
- 기본 모델이 있어야 최적화 기법 적용후 얼마나 성능이 더 좋아졌는지 비교해볼 수 있음
2-1) 환경 설정
- 시드값 고정 - 결과 재현을 위한 작업
- GPU 장비 설정
- 훈련 속도를 높이기 위해 데이터를 GPU 처리하도록 설정
2-2) 데이터 준비
- 훈련/검증 데이터 분리
- 데이터 증강

- 이미지를 변환해 데이터 개수를 늘리는 기법
- 이미지 개수가 부족한 상황에서 유용한 방법
- 여러 데이터 증강 패키지 존재
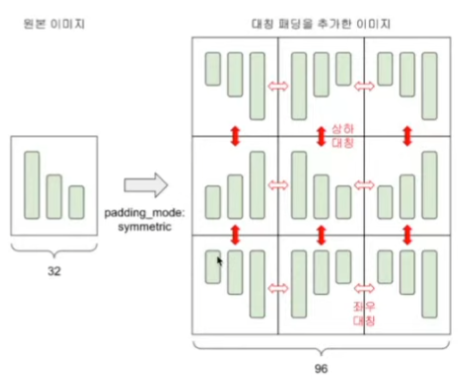
- torchvision.transforms 변환기

- transforms.Pad(32, padding_mode=’symmetric’) <- 패딩추가
- albumentations 변환기

- 예제 사이트
매 epoch 마다 적용하면 동일한 원본 이미지라도 새로운 학습의 효과를 얻음
이미지 사이즈의 크기를 키웠을때 성능이 높아지는 경향이 있다고 함!
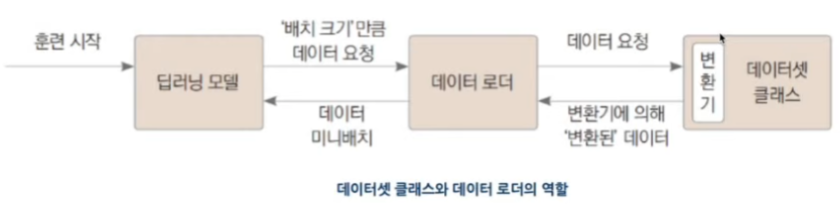
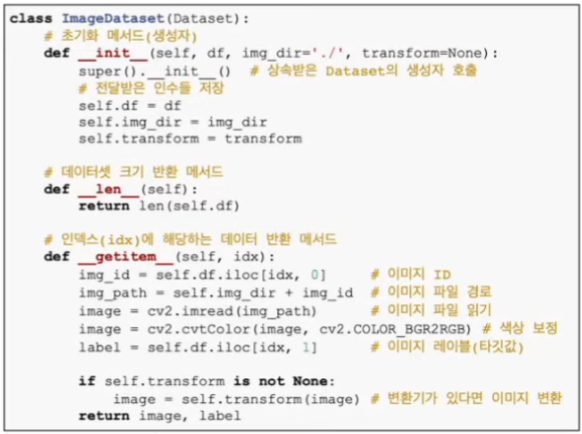
- 데이터셋 클래스 정의
- 변환기 전달
- __ len __ 과 __ getitem __ 필수!
- __ len __ : 데이터셋 크기 반환하는 메서드
- __ getitem __ : 인덱스를 인수로 받아, 그 인덱스에 해당하는 데이터를 반환하는 메서드
- 데이터 증강도 함께 적용할 수 있음

사용자 정의 데이터셋 클래스를 만들 때 Dataset 추상 클래스를 꼭 상속받아야 하는지?
필수는 아님, __ len __ () 과 __ getitem __ () 메서드만 동일하게 정의한다면 상속 받지 않아도 동작
하지만, 코드의 의도를 명확하게 하기 위해서는 Dataset을 상속받는 것이 바람직함
- 데이터셋 생성
- 데이터 로더 생성
결과물 : 훈련/검증용 데이터 로더 및 데이터셋
2-3) 모델 생성

- 딥러닝 모델 직접 구현/설계
- torchvision.models 모듈
- pretrainedmodels 모듈
- 기타 가용한 모듈 검색해 사용
미리 정의된 모델을 가져와서 사용하는 것이 좋음
EDA 와 베이스라인 모델 설계 체크리스트
- 데이터 증강을 어느정도 까지 해야하는지?
데이터 증강은 너무 많이하면 오버피팅, 적정 지점을 찾는것이 정형화 되어 있지 않아서 검증데이터를 확인해서 파악하는 방법사용
3. 딥러닝 모델 성능 개선 프로세스
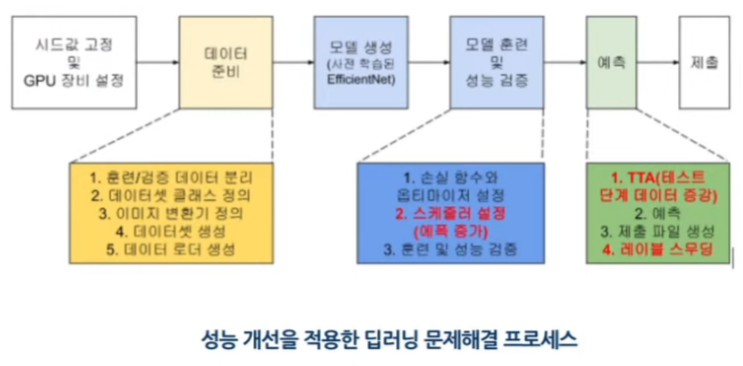
- 크게 두개로 나눔, 훈련단계-예측단계
3-1) 훈련 단계 최적화
- 손실 함수
- 옵티마이저
- 딥러닝 학습이 올바른 방향으로 학습하게 해주는 것
- adam이 최고? -> adam 계열인 Adamax, AdamW 도 좋음
- 스케줄러
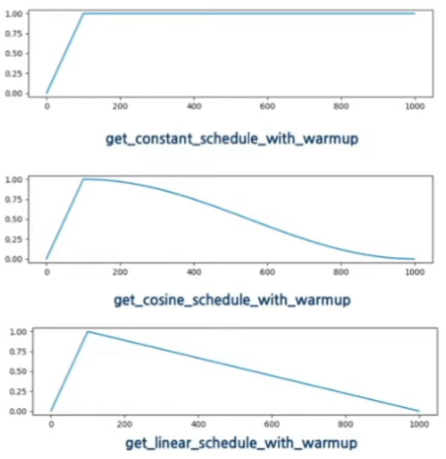
get_cosin_schedule 이 좋았다고 하심 !
훈련 초기와 훈련 말미에 변화를 완만하게 하면 좋은 결과를 얻었음
- 학습률을 조절하는 것
- epoch 조절
2) 예측 단계 최적화
- 테스트 단계 데이터 증강(TTA)
- 테스트 데이터에 여러 변환 적용
- 변환한 테스트 데이터별로 타깃 확률값 예측
- 타깃 예측 확률의 평균 구하기
이렇게 하면 앙상블 효과가 있어서 원본 데이터로 한 차례만 예측할 때보다 성능이 좋아짐

- 변환된 target 값 여러게 사용한것이 성능을 잘 예측할수 있음
- 안좋아지는 경우도 존재
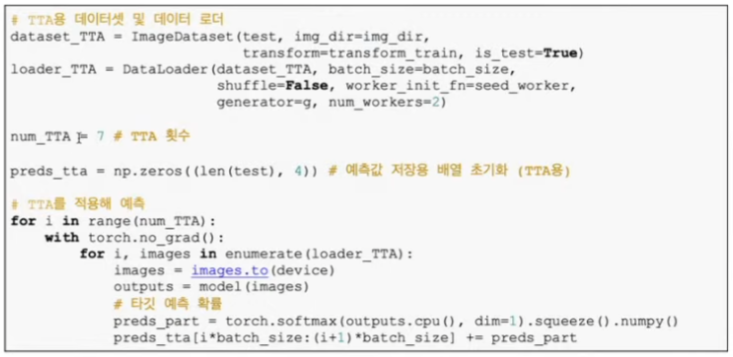
- num_TTA : 5~7 정도 추천
- 레이블 스무딩
- 과잉 확신한 타깃 확률값을 보정하는 기법
- 확신이 과하면 일반화 성능이 떨어질 우려가 있음
- 수식

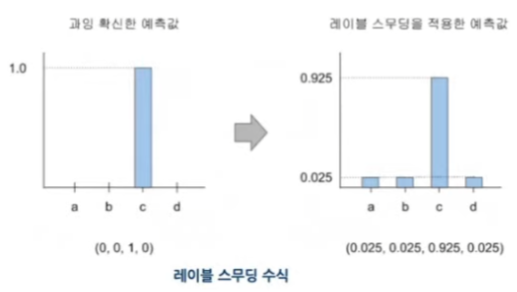
- 왼쪽과 같은 예측이 오른쪽 처럼 변화
- 100% 성능 향상은 아님

딥러닝 문제해결 전체 체크리스트

강의 후기
이전의 머신러닝 패턴 세미나와 같이 입문할 때 매우 좋은 강의였습니다.
필요한 점이나 확인해야 하는 점을 꼼꼼하게 집어주신 것 같습니다.