
SPACE-S
팔로워11명
주최대회0개
경진대회
전체보기
경진대회
종료
제6회 2024 연구개발특구 AI SPARK 챌린지
SPACE-S
1600만원
제6회 2024 연구개발특구 AI SPARK 챌린지
SPACE-S
1600만원

경진대회
종료
제5회 2023 연구개발특구 AI SPARK 챌린지 - 사회문제해결형
SPACE-S
800만원
제5회 2023 연구개발특구 AI SPARK 챌린지 - 사회문제해결형
SPACE-S
800만원

경진대회
종료
안내 | 제5회 2023 연구개발특구 AI SPARK 챌린지
SPACE-S
800만원
안내 | 제5회 2023 연구개발특구 AI SPARK 챌린지
SPACE-S
800만원

경진대회
종료
제4회 2023 연구개발특구 AI SPARK 챌린지 - 공기압축기 이상 판단
SPACE-S
800만원
제4회 2023 연구개발특구 AI SPARK 챌린지 - 공기압축기 이상 판단
SPACE-S
800만원

경진대회
종료
안내 | 제4회 2023 연구개발특구 AI SPARK 챌린지
SPACE-S
800만원
안내 | 제4회 2023 연구개발특구 AI SPARK 챌린지
SPACE-S
800만원

경진대회
종료
[2023 연구개발특구 AI SPARK 챌린지] 인공지능 경진대회 수요기업 모집
SPACE-S
[2023 연구개발특구 AI SPARK 챌린지] 인공지능 경진대회 수요기업 모집
SPACE-S

경진대회
종료
[2023 연구개발특구 AI SPARK 챌린지] 인공지능 경진대회 온라인 설명회
SPACE-S
[2023 연구개발특구 AI SPARK 챌린지] 인공지능 경진대회 온라인 설명회
SPACE-S

경진대회
종료
[Space-S x KaKR] 그래프 러닝 및 해커톤
SPACE-S
525만원
[Space-S x KaKR] 그래프 러닝 및 해커톤
SPACE-S
525만원

경진대회
종료
제3회 연구개발특구 AI SPARK 챌린지
SPACE-S
900만원
제3회 연구개발특구 AI SPARK 챌린지
SPACE-S
900만원

경진대회
종료
제2회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지
SPACE-S
900만원
제2회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지
SPACE-S
900만원

경진대회
종료
[AI SPARK 챌린지] 대회2. 수도관 누수 탐지 분류 문제
SPACE-S
800만원
[AI SPARK 챌린지] 대회2. 수도관 누수 탐지 분류 문제
SPACE-S
800만원

경진대회
종료
[AI SPARK 챌린지] 대회1. 섬진강 유역 내 강우량 예측 문제
SPACE-S
800만원
[AI SPARK 챌린지] 대회1. 섬진강 유역 내 강우량 예측 문제
SPACE-S
800만원

경진대회
종료
제1회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지 : ESG 혁신
SPACE-S
1,600만원
제1회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지 : ESG 혁신
SPACE-S
1,600만원
세미나
전체보기
세미나
참가 접수중
진행중
제6회 2024 연구개발특구 AI SPARK 챌린지 수상 모델 공개
SPACE-S
제6회 2024 연구개발특구 AI SPARK 챌린지 수상 모델 공개
SPACE-S

세미나
종료
매너스 심층분석 오프라인 세미나
SPACE-S
매너스 심층분석 오프라인 세미나
SPACE-S

세미나
종료
생성형 AI를 활용한 문서 자동화 및 콘텐츠 생성 전략
SPACE-S
생성형 AI를 활용한 문서 자동화 및 콘텐츠 생성 전략
SPACE-S

세미나
종료
AI Agent, 스타트업의 게임체인저
SPACE-S
AI Agent, 스타트업의 게임체인저
SPACE-S

세미나
종료
생성형 AI를 활용한 경영 데이터 분석
SPACE-S
생성형 AI를 활용한 경영 데이터 분석
SPACE-S

세미나
종료
[25년 1월 7일] 생성형 AI를 활용한 콘텐츠 마케팅 자동화의 거의 모든 것
SPACE-S
[25년 1월 7일] 생성형 AI를 활용한 콘텐츠 마케팅 자동화의 거의 모든 것
SPACE-S

세미나
종료
ChatGPT와 오피스를 활용한 업무 생산성 향상 전략
SPACE-S
ChatGPT와 오피스를 활용한 업무 생산성 향상 전략
SPACE-S

세미나
종료
[대덕특구] SPACE-S 생성형AI 세미나 안내
SPACE-S
[대덕특구] SPACE-S 생성형AI 세미나 안내
SPACE-S

세미나
종료
[25년 1월 14일 세미나] Automated Paper Reviewer
SPACE-S
[25년 1월 14일 세미나] Automated Paper Reviewer
SPACE-S

세미나
종료
생성형AI Prompt 어시웍스 실무 적용법
SPACE-S
생성형AI Prompt 어시웍스 실무 적용법
SPACE-S

세미나
종료
의료현장에서 LLM을 통한 생산/효율성 향상 방법
SPACE-S
의료현장에서 LLM을 통한 생산/효율성 향상 방법
SPACE-S

세미나
종료
제6회 INNOPOLIS SPACE-S Meet-Up Day
SPACE-S
제6회 INNOPOLIS SPACE-S Meet-Up Day
SPACE-S

세미나
종료
테스트
SPACE-S
테스트
SPACE-S

세미나
종료
[DLD 2022] 하이퍼파라미터 튜닝과 ML 파이프라인 - 박찬성
SPACE-S
[DLD 2022] 하이퍼파라미터 튜닝과 ML 파이프라인 - 박찬성
SPACE-S

세미나
종료
[DLD 2022] EDSR Super-resolution 소개 및 Keras 코드 실습
SPACE-S
[DLD 2022] EDSR Super-resolution 소개 및 Keras 코드 실습
SPACE-S

세미나
종료
[DLD 2022] 이미지를 어떻게 표현할 수 있는가 - 임훈
SPACE-S
[DLD 2022] 이미지를 어떻게 표현할 수 있는가 - 임훈
SPACE-S

세미나
종료
[DLD 2022] Tensorflow Decision Forests 를 이용한 분류모델 만들기 - 이동훈
SPACE-S
[DLD 2022] Tensorflow Decision Forests 를 이용한 분류모델 만들기 - 이동훈
SPACE-S

세미나
종료
[DLD 2022] Tensorflow Decision Forests 를 이용한 Text Classification - 이동훈
SPACE-S
[DLD 2022] Tensorflow Decision Forests 를 이용한 Text Classification - 이동훈
SPACE-S

세미나
종료
[DLD 2022] Augmenting Convolutional networks with attention-based aggregation - 고승희
SPACE-S
[DLD 2022] Augmenting Convolutional networks with attention-based aggregation - 고승희
SPACE-S

세미나
종료
[DLD 2022] Keras Trainer pattern 세미나 - 허지완
SPACE-S
[DLD 2022] Keras Trainer pattern 세미나 - 허지완
SPACE-S

세미나
종료
[DLD 2022] Structured data learning with TabTransformer - 박성수
SPACE-S
[DLD 2022] Structured data learning with TabTransformer - 박성수
SPACE-S

세미나
종료
[DLD 2022] 정신차려 이 모델이 커져만 가는 각박한 세상 속에서 : ViT knowledge distillation 해보기 - 박정현
SPACE-S
[DLD 2022] 정신차려 이 모델이 커져만 가는 각박한 세상 속에서 : ViT knowledge distillation 해보기 - 박정현
SPACE-S

세미나
종료
[DLD 2022] 케라스 NLP를 활용한 GPT 텍스트 생성 도전하기 - 최태균
SPACE-S
[DLD 2022] 케라스 NLP를 활용한 GPT 텍스트 생성 도전하기 - 최태균
SPACE-S

세미나
종료
[DLD 2022] Keras 기반 Stable Diffusion을 이미지를 생성해보자 - 박찬성
SPACE-S
[DLD 2022] Keras 기반 Stable Diffusion을 이미지를 생성해보자 - 박찬성
SPACE-S

세미나
종료
[DLD 2022] Train a Vision Transformer on small datasets - 박은수
SPACE-S
[DLD 2022] Train a Vision Transformer on small datasets - 박은수
SPACE-S

세미나
종료
[DLD 2022] English speaker accent recognition using Transfer Learning - 소준섭
SPACE-S
[DLD 2022] English speaker accent recognition using Transfer Learning - 소준섭
SPACE-S

세미나
종료
[DLD 2022] Denoising Diffusion Implicit Models - 박수철
SPACE-S
[DLD 2022] Denoising Diffusion Implicit Models - 박수철
SPACE-S

세미나
종료
[DLD 2022] Bert 보다 빠르다? FNet으로 Text Classification 해보기 - 김노은
SPACE-S
[DLD 2022] Bert 보다 빠르다? FNet으로 Text Classification 해보기 - 김노은
SPACE-S

세미나
종료
[DLD 2022] 요즘 핫한 생성모델 stable diffusion 찍먹해보기 - 김형섭
SPACE-S
[DLD 2022] 요즘 핫한 생성모델 stable diffusion 찍먹해보기 - 김형섭
SPACE-S

세미나
종료
[DLD 2022] 눈으로 보자 Attention - 최현영
SPACE-S
[DLD 2022] 눈으로 보자 Attention - 최현영
SPACE-S

세미나
종료
[DLD 2022] Advanced Augmentation Strategy in Keras - 김종석
SPACE-S
[DLD 2022] Advanced Augmentation Strategy in Keras - 김종석
SPACE-S

세미나
종료
[DLD 2022] 허깅페이스로 나만의 BERT Pretraining 해보기 - 윤주성
SPACE-S
[DLD 2022] 허깅페이스로 나만의 BERT Pretraining 해보기 - 윤주성
SPACE-S

세미나
종료
[DLD 2022] Attention mechanism이 없는 Vision Transformer를 상상해보셨나요? - 배성수
SPACE-S
[DLD 2022] Attention mechanism이 없는 Vision Transformer를 상상해보셨나요? - 배성수
SPACE-S

세미나
종료
[DLD 2022] Question Answering with Hugging Face Transformers - 배성수
SPACE-S
[DLD 2022] Question Answering with Hugging Face Transformers - 배성수
SPACE-S

세미나
종료
[DLD 2022] 허깅페이스로 나만의 요약 모델 만들기 - 윤주성
SPACE-S
[DLD 2022] 허깅페이스로 나만의 요약 모델 만들기 - 윤주성
SPACE-S

세미나
종료
[DLD 2022] 사람이 하는 번역, 인공지능이 하는 번역 - 김영하
SPACE-S
[DLD 2022] 사람이 하는 번역, 인공지능이 하는 번역 - 김영하
SPACE-S

세미나
종료
[DLD 2022] Pascal VOC 2007로 알아보는 객체 감지 모델 기초 - 김영하
SPACE-S
[DLD 2022] Pascal VOC 2007로 알아보는 객체 감지 모델 기초 - 김영하
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - 이미지 분류를 위한 딥러닝 문제해결 패턴
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나 - 이미지 분류를 위한 딥러닝 문제해결 패턴
SPACE-S

세미나
종료
[그래프 러닝 및 해커톤] 파이썬 베이스라인 따라하기 - 연습
SPACE-S
[그래프 러닝 및 해커톤] 파이썬 베이스라인 따라하기 - 연습
SPACE-S

세미나
종료
[그래프 러닝 및 해커톤] 파이썬 베이스라인 따라하기 - 준비
SPACE-S
[그래프 러닝 및 해커톤] 파이썬 베이스라인 따라하기 - 준비
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - 정형 데이터를 다루는 머신러닝 문제해결 패턴
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나 - 정형 데이터를 다루는 머신러닝 문제해결 패턴
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나-TESLA 자율주행 기술에 발가락 담그기
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나-TESLA 자율주행 기술에 발가락 담그기
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - 라벨링 없이 해보는 의미론적 분할
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나 - 라벨링 없이 해보는 의미론적 분할
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - GCP와 TFX로 쉽게 MLOps를 시작하는법
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나 - GCP와 TFX로 쉽게 MLOps를 시작하는법
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - MLOps와 높은 진입 장벽
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나 - MLOps와 높은 진입 장벽
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - 신뢰가능한 딥러닝을 향하여
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나 - 신뢰가능한 딥러닝을 향하여
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - 추천시스템 더 알아보기
SPACE-S
INNOPOLIS AI SPACE-S 인공지능 세미나 - 추천시스템 더 알아보기
SPACE-S

세미나
종료
INNOPOLIS AI SPACE-S 인공지능 세미나 - 추천시스템 입문하기
SPACE-S
기프티콘
INNOPOLIS AI SPACE-S 인공지능 세미나 - 추천시스템 입문하기
SPACE-S
기프티콘

세미나
종료
[Learning] 엣지 디바이스에서의 영상 분류 및 물체 탐지 (NVIDIA Jetson)
SPACE-S
[Learning] 엣지 디바이스에서의 영상 분류 및 물체 탐지 (NVIDIA Jetson)
SPACE-S

세미나
종료
[Learning] 아이에게 인공지능 게임 만들어주기
SPACE-S
[Learning] 아이에게 인공지능 게임 만들어주기
SPACE-S
트레이닝
전체보기
참가 접수중
진행중
숫자손글씨 직접 분류해보기
SPACE-S
숫자손글씨 직접 분류해보기
SPACE-S

참가 접수중
진행중
알파벳 수화 직접 배워보기
SPACE-S
알파벳 수화 직접 배워보기
SPACE-S

참가 접수중
진행중
패션 아이템 이미지 분류하기
SPACE-S
학습용
패션 아이템 이미지 분류하기
SPACE-S
학습용

참가 접수중
진행중
딥러닝으로 은하 분류하기
SPACE-S
딥러닝으로 은하 분류하기
SPACE-S

참가 접수중
진행중
머신러닝을 통한 당뇨병 예측
SPACE-S
머신러닝을 통한 당뇨병 예측
SPACE-S

참가 접수중
진행중
리뷰 데이터 감성 분석
SPACE-S
리뷰 데이터 감성 분석
SPACE-S

참가 접수중
진행중
타이타닉 생존자 예측하기
SPACE-S
타이타닉 생존자 예측하기
SPACE-S
챗봇
전체보기게시글
전체보기
SPACE-S 세미나 : 생성형AI를 활용한 생산성 향상 방안
안녕하세요. 김태영입니다. 생성형AI를 활용한 생산성 향상 방안이라는 주제로 SPACE-S 세미나를 2024년 7월 2일 16:10~17:00에 대전 SPACE-S AI 코워킹스페이스에서 발표합니다. 주제는 생성AI트렌드와 활용사례 소개이긴 하나 활용사례 중에 스타트업에서 활용 가능한 고객관리, 프로젝트 관리, 액션아이템 관리 쪽으로 발표할 예정입니다. 많은 관심 부탁드립니다. 신청링크 : https://event-us.kr/spaces/event/86347

MIoU 평가지표
MIoU 평가지표안녕하세요 저는 Semantic Segmentation의 대표적인 평가지표 MIoU에 대해 소개해드리려고 합니다.먼저 IoU(Intersection over Union)는 실제 객체가 존재하는 박스와 모델이 객체라고 인식한 박스가 얼마나 차이 나는지를 표현한 값으로 다음과 같이 나타낼 수 있습니다.즉 객체라고 인식한 박스와 실제 객체가 존재하는 박스의 합집합 중 교집합이 속하는 영역의 넓이로 볼 수 있는데요 예를 들어 다음과 같이 초록색 박스(GT) 와 모델이 평가한 빨간색 박스가 있다고 가정할 때(infered) 초록색 박스 크기와 빨간색 박스 크기를 합한 넓이 중 두 박스가 겹치는 부분의 넓이가 차지하는 비율을 구하여 IoU를 구할 수 있습니다. Object Detection task에서는 IoU의 값이 1에 가깝다는 의미는 두 박스가 일치하다는 뜻과 일맥상통하기에 1에 가까울수록 좋은 성능을 가진다고 평가합니다. *Overlapping Area(교집합 영역 넓이)*Union area(합집합 영역 넓이): area(green box)+area(red box) - Overlapping Area 그렇다면 MIoU란 무엇일까요?MIoU란 mean Intersection over Inion으로 IoU의 평균 값을 의미합니다. 보통 모델은 여러가지 평가 데이터 셋을 통해 평가되어지는데 결국 좋은 성능인 모델이라고 말하기 위해서 많은 평가 데이터에 대해 높은 IoU 값을 보여야 합니다. 따라서 모델의 평균 성능을 평가하기 위해 이미지에 대한 IoU값을 측정한 후 평균을 계산하여 MIoU를 구하게 되는 것입니다. 위와 같은 평가 지표는 Object Detection 또는 Semantic Segmentation 모델에 대해 성능 평가 지표로 많이 사용됩니다.
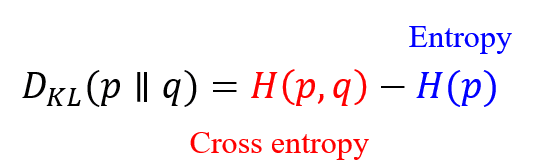
What kind of loss function do we have to use?
손실함수는 신경망 모델이 각 훈련 배치에서 전체 오류를 계산하는 방법을 정의합니다. 따라서 역전파를 수행할 때 내부 가중치가 조정되는 과정에 영향을 미치므로 전체 모델 성능에도 중요한 영향을 미칩니다. 이미지 분할 및 분류 작업에 대한 기본적인 손실 함수는 BCE ( 이진 교차 엔트로피 ) 입니다. Dice 계수 혹은 IoU 손실 함수가 사용되는 상황에서도 기본적인 베이스라인으로 BCE를 사용합니다. 손실 함수는 역전파가 거슬러 올라가는 동안 모델 전체에서 계산되어야 하는 텐서에서 작동해야 하므로 Numpy로 간단하게 계산될 수 없습니다. 해당 모델 라이브러리에서 제공하는 함수를 사용해야 합니다. Keras에서는 k.sum()과 같은 함수를 사용합니다. 그라디언트 계산은 모델 라이브러리에 의해 자동으로 계산되지만, 필요한 경우 수동으로 정의할 수 있습니다. 다중 클래스 분류 및 분할에서는 전체 손실대신에 각 클래스의 평균 손실을 계산하는 손실 함수를 사용합니다. 1. Distributation-based loss ( 분포 기반 손실 함수 )Cross entropy (CE) 크로스 엔트로피는 Kullback-Leibler(KL) divergence라는 두 분포 사이의 비유사성에 대한 측정값입니다. 일반적인 기계 학습에서는 데이터 분포는 훈련 데이터에의해 제공되므로 H(p)는 상수입니다.가중 교차 엔트로피는 CE의 확장된 버전으로 각 클래스에 다른 가중치를 할당합니다. 일반적으로 제시되지 않은 클래스에는 더 큰 가중치가 할당됩니다.TopK loss는 네트워크가 훈련 중에 까다로운 샘플에 집중하도록 하는 것을 목표로 합니다.초점 손실은 잘 분류된 예제에 할당된 손실이 감소되는 극단적인 전경-배경 클래스 불균형을 처리하기 위해 표준 CE를 적용합니다.거리 패널티 CE 손실 가중치는 실제 마스크에서 파생된 거리 맵에 의해 엔트로피를 교차합니다. 분할하기 어려운 경계 영역으로 네트워크의 초점을 안내하는 것을 목표로 합니다. 2. BCE-DICE Loss (BCE-Dice 결합 손실 함수) 이 손실은 이미지 분할 모델 손실 함수로서 기본값인 표준 이진 교차 엔트로피(BCE) 손실과 주사위 손실을 결합합니다. 두 가지 방법을 결합하면 손실의 다양성을 허용하면서 BCE의 안정성을 활용할 수 있습니다. 다중 클래스 BCE에 대한 방정식 자체는 로지스틱 회귀를 연구자에게 친숙한 개념이다. 3. Region-based loss (영역 기반 함수)영역 기반 손실 함수는 정답과 예측된 분할 간의 불일치를 최소화하거나 중첩 영역을 최대화하는 것을 목표로 합니다.민감도-특이성(SS) 손실은 민감도와 특이성의 평균 제곱 차이의 가중치 합입니다. 불균형 문제를 해결하기 위해 SS는 특이성에 더 높은 가중치를 부여합니다.주사위 손실은 가장 일반적으로 이미지 분할에 사용되는 평가 지표인 주사위 계수를 직접 최적화합니다.Dice 손실과 유사한 IoU 손실(Jaccard 손실이라고도 함)은 세분화 메트릭을 직접 최적화하는 데에도 사용됩니다.Tversky 손실은 FN(False Negative) 및 FP(False Positive)에 서로 다른 가중치를 설정합니다. 이는 FN 및 FP에 대해 동일한 가중치를 사용하는 주사위 손실과 다릅니다.일반화된 주사위 손실은 각 클래스의 가중치가 레이블 빈도의 제곱에 반비례하는 Dice 손실의 다중 클래스 확장입니다.초점 트버스키 손실은 초점 손실의 개념을 적용하여 확률이 낮은 희귀한 케이스에 초점을 맞춥니다.페널티 손실은 일반화된 주사위 손실에서 위음성 및 위양성에 높은 페널티를 제공하는 손실 함수입니다. 4. Dice Loss주사위 계수는 가장 일반적으로 이미지 분할에 사용되는 평가 지표이며, 이에 최적화 된 손실 함수입니다. 5. Jaccard/Intersection over Union (IoU) Loss -> IoU 손실 함수IoU 평가 지표는 주사위 지표와 비슷하며 교집합 대비 합집하의 비율로 계산된다. 주사위 지표와 함께 이미지 분할 모델에서 가장 많이 쓰이는 지표(수단)이다. 6. Focal LossFocal Loss는 2017년 Facebook AI Research의 Lin et al에 의해 양성 사례가 상대적으로 드물었던 극도로 불균형한 데이터 세트를 해결하기 위한 수단으로 도입되었습니다. 그들의 논문 "Focal Loss for Dense Object Detection"은 https://arxiv.org/abs/1708.02002에서 검색할 수 있습니다. 실제로 연구원들은 함수의 알파 수정 버전을 사용했기 때문에 이 구현에 포함시켰습니다. 7. Tversky Loss트베르스키 손실은 https://arxiv.org/abs/1706.05721 에서 검색할 수 있는 "3D 완전 컨볼루션 심층 네트워크를 사용하는 이미지 분할을 위한 Tversky 손실 함수"에 소개되었습니다. 손실 함수에서 서로 다른 유형의 오류가 얼마나 심하게 처벌되는지를 조정할 수 있는 상수를 활용하여 불균형 의료 데이터 세트에 대한 분할을 최적화하도록 설계되었습니다. 논문에서:... α=β=0.5의 경우 Tversky 지수는 F1 점수와 동일한 주사위 계수와 동일하도록 단순화됩니다. α=β=1일 때 방정식 2는 Tanimoto 계수를 생성하고 α+β=1로 설정하면 Fβ 점수 세트를 생성합니다. β가 클수록 정밀도보다 재현율이 더 높습니다(위음성에 더 중점을 둠).요약하자면, 이 손실 함수는 값이 증가함에 따라 손실 함수에서 더 높은 정도로 위양성 및 위음성 각각에 페널티를 주는 상수 '알파' 및 '베타'에 의해 가중치가 부여됩니다. 특히 베타 상수는 모델이 매우 보수적인 예측을 통해 오도할 정도로 긍정적인 성능을 얻을 수 있는 상황에서 적용됩니다. 최적의 값을 찾기 위해 다양한 값으로 실험할 수 있습니다. alpha==beta==0.5에서 이 손실은 Dice Loss와 동일해집니다. 8. Focal Tversky Loss트베르스키 손실의 변형으로서 초점 손실의 감마 수정자를 포함한다. 9. Lovasz Hinge Loss로바즈 힌지 손실 함수는 Berman, Triki 및 Blaschko의 논문 "The Lovasz-Softmax loss: A tractable surrogate for optimize of cross-over-union measure in neural network"에서 소개되었으며 여기에서 검색할 수 있습니다: https://arxiv.org/abs/1705.08790.특히 다중 분류의 경우 의미론적 분할을 위해 Intersection over Union 점수를 최적화하도록 설계되었습니다. 특히 각 오류가 IoU 점수에 미치는 영향을 누적 계산하기 전에 오류를 기준으로 예측을 정렬합니다. 그런 다음 이 그래디언트 벡터에 초기 오류 벡터를 곱하여 IoU 점수를 가장 많이 감소시킨 예측에 가장 강력한 페널티를 부여합니다. 이 절차는 jeanderbleu의 탁월한 요약 에서 자세히 설명되어 있습니다.이 코드는 https://github.com/bermanmaxim/LovaszSoftmax 작성자의 github에서 직접 가져왔으며 모든 크레딧은 이들에게 있습니다.원본 손실 함수 외에도 PyTorch에 대한 입력으로 재구성된 랭크 1 텐서를 사용하는 플랫 변형을 구현했습니다. 필요에 따라 데이터의 차원과 클래스 번호에 따라 수정할 수 있습니다. 이 코드는 원시 로짓을 사용하므로 손실 계산 전에 모델에 활성화 레이어가 포함되어 있지 않은지 확인해야 합니다.간결함을 위해 연구원의 코드를 아래에 숨겼습니다. 손실이 작동하려면 커널에 로드하기만 하면 됩니다. tensorflow 구현의 경우 여전히 Keras와 호환되도록 노력하고 있습니다. Tensorflow와 Keras 함수 라이브러리 사이에는 이를 복잡하게 만드는 차이점이 있습니다. 10. Combo Loss콤보 손실은 Taghanaki 등의 논문 "Combo loss: Handling input and output 불균형 in multi-organ segmentation"에서 소개되었으며 여기에서 검색할 수 있습니다: https://arxiv.org/abs/1805.02798.콤보 손실은 Tversky 손실과 마찬가지로 거짓 긍정 또는 거짓 부정에 각각 페널티를 주는 추가 상수가 있는 수정된 교차 엔트로피 함수와 주사위 손실의 조합입니다.( 결합 함수) 11. Boundary--based loss최근 새로운 유형의 손실 함수인 경계 기반 손실은 정답과 예측 간의 거리를 최소화하는 것을 목표로 합니다. 일반적으로 더 나은 결과를 위해서 경계 기반 손실 함수가 영역 기반 손실과 함께 사용됩니다. 12. Compound loss여러종류의 손실함수를 결합함으로서, 우리는 혼합된(결합된) 손실 함수를 얻을 수 있습니다. (ex Dice+CE, Dice + Focal, Dice + IOU )... 모든 종류의 손실 함수들은 플러그 방식으로(조립 및 결합) 사용할 수 있습니다.
Instruction Tuning LLM
The Limits of LLMs First, let’s briefly review how Large Language Models (LLMs) are created. A variety of text data, such as news, blogs, novels, technical books, and subtitles, is collected. This data undergoes various preprocessing steps like cleaning and deduplication to create the training dataset. This dataset is then fed into an empty LLM shell, training it to predict the next word in a sequence. This trained LLM can then use the input data to predict outcomes, and by feeding its outputs back as inputs, it can generate extended sequences of text. While the actual development process of LLMs is far more complex and involves many tasks, this simplification helps illustrate the general flow. We refer to such completed models as pre-trained or foundation models.Despite the vast knowledge and information accumulated within these pre-trained models, there is a significant issue in retrieving this knowledge effectively. As you might have noticed during the training description, LLMs based on the GPT architecture learn statistical patterns from massive text data and predict subsequent information based on previous data—a causal language model. Thus, they don't combine knowledge contextually like humans but generate the next word based on probabilities from preceding sentences.For example, if given the input "King Sejong using a MacBook," a typical pre-trained model might unabashedly generate "King Sejong made a report using a MacBook," because "report" was the statistically likely next word following "MacBook."This phenomenon, known as hallucination, is a fundamental issue with GPT-based LLMs. Various methods are being explored to address these challenges, with fine-tuning and in-context learning being the most common. Before discussing instruction tuning, let’s delve into these two techniques.In-Context Learning vs. Fine-Tuning Fine-tuning, discussed in a previous post, involves updating the model with a specific dataset to produce desired outputs. In-context learning, or prompt learning, recognizes the contextual meaning within a prompt and generates outputs accordingly. This approach tries to achieve desired outputs without updating the model but by crafting well-designed prompts.Examples of In-Context Learning:Zero-shot learning: The model answers a task immediately without prior examples.Prompt: "Analyze the emotion of the sentence: 'This movie is so boring.'"GPT: "It expresses a negative emotion."One-shot learning: The model performs a task with one example.Prompt: "This movie is so boring" -> Negative "This movie was dull" ->GPT: NegativeFew-shot learning: If one example isn’t enough, several are given.Prompt: "This movie is so boring" -> Negative "This movie is just okay" -> Neutral "This movie was really fun?" -> Positive "This movie is exciting" ->GPT: PositiveGPT-3 and other large LLMs can adapt to unseen data through prompts, leveraging their extensive knowledge and linguistic capabilities. Prompt engineering involves meticulously crafting prompts to extract and properly format the model’s output according to user intent.Instruction Tuning Combining the benefits of both fine-tuning and in-context learning, instruction tuning aims to enhance the model’s flexibility and accuracy. It involves training the model with a dataset comprising specific instructions and appropriate model responses, enabling the model to respond correctly to direct queries and elaborated instructions, much like in-context learning with example-based guidance.Alpaca A prominent example of applying instruction tuning to LLMs is Stanford’s Alpaca model, based on Meta’s LLaMA and fine-tuned with an instruction-based dataset. Initially, human-generated instruction samples guided the dataset creation, significantly reducing the time and effort involved by subsequently allowing the LLM (like GPT-3) to generate similar datasets itself (self-instruction).

Semantic Segmentation Paper List
Semantic Segmentation task와 관련하여 읽어볼 만한 CVPR2024 논문들입니다. 관심있으신 분들은 논문을 직접 읽어 봐도 좋을 것 같습니다. SemiCVT: Semi-Supervised Convolutional Vision Transformer for Semantic Segmentation HPL-ESS: Hybrid Pseudo-Labeling for Unsupervised Event-based Semantic Segmentation Frequency-Adaptive Dilated Convolution for Semantic Segmentation ContextSeg: Sketch Semantic Segmentation by Querying the Context with Attention SED: A Simple Encoder-Decoder for Open-Vocabulary Semantic Segmentation
베이스라인 함수 분석
1. 이미지 및 마스크 처리 함수1.1 get_img_arr(path)이 함수는 지정된 경로에서 이미지 파일을 열고, Rasterio 라이브러리를 사용하여 이미지 데이터를 읽습니다. 이 데이터는 (높이, 너비, 채널) 형식으로 변환되고, 모든 픽셀 값은 최대 픽셀 값(65535)으로 정규화됩니다. 정규화는 모델 학습에 있어 일반적으로 중요한 단계로, 다양한 이미지 간의 밝기 및 대비 차이를 줄이고 모델의 수렴 속도를 향상시키는 데 도움이 됩니다.1.2 get_img_762bands(path)이 함수는 특정 밴드(7, 6, 2) 데이터만 불러오는 특화된 버전입니다. 일부 위성 이미지 처리에서는 특정 밴드가 특정 유형의 정보(예: 식생, 수분, 지형 등)를 포함하고 있어 이 밴드들만 사용하여 모델을 학습시키기도 합니다. 이 함수 역시 데이터를 정규화하여 반환합니다.1.3 get_mask_arr(path)마스크 데이터를 처리하는 이 함수는 마스크 이미지(일반적으로 지상 진실 데이터를 나타냄)를 불러와 배열로 변환합니다. 이 데이터는 일반적으로 픽셀별 분류 작업(예: 픽셀이 특정 클래스에 속하는지 여부)에 사용됩니다.2. 데이터 제너레이터2.1 threadsafe_generator(f)멀티스레딩 환경에서 데이터 로드 작업을 안전하게 처리하기 위해 사용하는 데코레이터입니다. 파이썬에서 제너레이터는 기본적으로 스레드 안전하지 않기 때문에, 이 데코레이터를 통해 여러 스레드에서 동시에 접근해도 문제가 발생하지 않도록 합니다.2.2 generator_from_lists(images_path, masks_path, batch_size=32, shuffle=True, random_state=None, image_mode='10bands')이 함수는 이미지와 마스크의 경로 리스트를 입력으로 받아, 배치 단위로 데이터를 불러와 반환하는 제너레이터를 생성합니다. shuffle 옵션을 사용하여 데이터를 무작위로 섞어, 각 배치가 다양한 데이터를 포함하도록 하여 과적합을 방지합니다. image_mode 파라미터를 통해 사용할 이미지 처리 함수를 선택할 수 있습니다(get_img_arr 또는 get_img_762bands).3. 모델 훈련 및 검증3.1 모델 훈련(fit_generator)fit_generator는 제너레이터를 통해 생성된 데이터를 사용하여 모델을 훈련합니다. 이 함수는 에폭 수, 배치 크기, 검증 데이터 등을 설정할 수 있으며, EarlyStopping과 ModelCheckpoint 콜백을 사용하여 훈련 중 조기 종료와 최고 성능 모델의 저장을 관리합니다.4. 예측 및 결과 저장4.1 예측 실행훈련된 모델을 사용하여 테스트 데이터셋에 대한 예측을 수행합니다. 각 이미지에 대해 모델은 해당 픽셀이 특정 클래스에 속하는지 예측하며, 결과를 이진 마스크로 변환합니다. 여기서 임계값 처리는 모델 출력을 명확한 클래스 레이블로 변환하는 데 사용됩니다.4.2 결과 저장예측된 결과를 딕셔너리로 관리하고, 이를 파일로 저장합니다. 이 파일은 나중에 성능 평가나 시각화 등에 사용될 수 있습니다.

MMSegmentation
다양한 segmentation 모델을 구축해둔 MMSegmentation에 대해 소개하고자 합니다. github link : https://github.com/open-mmlab/mmsegmentation MMSegmentation은 OpenMMLab 오픈소스 프로젝트 팀이 구축한 segmentation 관련 라이브러리 입니다.Segmentation에서 널리 사용되는 다양한 모델, 데이터 셋, metric, visualize tool 까지 제공 합니다.Config 파일을 통해 본인이 원하는 모델 및 데이터 셋을 사용할 수 있습니다. MMSegmentation에서 제공되는 모델 및 데이터 셋원하는 모델, 데이터 셋이 있다면 구현하여 추가한다면 기존 모델과 데이터셋에 결합하여 사용할 수 있습니다.홈페이지에서 Tutorial도 제공하여 쉽게 따라 사용할 수 있습니다.

DeepLabV3, Pyramid Attention network
출처: https://www.kaggle.com/code/pe4eniks/jax-flax-optax-orbax-fire-segmentation-on-tpu Fire segmentation에 좋은 네트워크들이 있어서 소개드리고자 합니다. DeepLabV3, Pyramid Attention network(PAN) 인데요. 각각 2017년, 2018년에 투고된 논문으로 segmentation에서 좋은 성능을 보이는 모델 아키텍처들입니다. DeepLabV3의 구조는 다음과 같습니다. PAN의 구조는 다음과 같습니다. 두 모델다 백본으로 Resnet을 사용할 수 있고, PAN의 경우 skip connection을 활용하여 성능을 더 향상시킬 수 있습니다. 구현 코드는 출처에 첨부드립니다.

Semantic segmentation task에 대해
안녕하세요. 저는 이 챌린지의 task에 해당하는 semantic segmentation task에 대해서 소개해 드리려고 합니다. Semantic segmentation이란, 이미지의 각 픽셀들을 그 픽셀이 속한 클래스나 오브젝트로 분류하는 task를 말합니다. semantic이란 ‘의미론적’이라는 뜻으로, semantic segmentation task는 의미론적인 관점에서 각 픽셀을 분류하는 task라고 할 수 있겠습니다. 요즘 가장 핫한 모델은, Segment-Anything Model, 통칭 SAM입니다. SAM을 사용하면, 모델이 한 번도 본 적 없는 테스트 이미지에 대해서도 거의 완벽한 segmentation mask를 얻을 수 있습니다. 그렇다면 가장 널리 사용되는 데이터셋들은 뭐가 있을까요? ADE20K, PASCAL VOC 2012, Cityscapes 등이 있습니다. paperswithcode에 가셔서 해당 데이터셋들을 검색하면, 가장 성능이 높은 모델들을 볼 수 있습니다. Semantic segmentation의 evaluation metric으로는 주로 mIoU가 쓰입니다. 우선 IoU(intersection over union)은 두 region의 교집합을 말합니다. mIoU는 mean IoU로, 클래스별 IoU를 평균낸 것입니다. mIoU가 높으면, 더 많은 클래스에 대해 더 높은 정확도를 가지고 있다는 뜻입니다. 더 많은 설명은 이 분의 블로그에 있습니다.

DeeplabV3+ 모델 고찰
제 사용한 DeepLabV3+에 대한 좋은 문서가 있어 공유해볼려고 합니다.아키텍처를 사용하여 이미지의 각 픽셀에 의미적 라벨을 할당하는 컴퓨터 비전 작업인 다중 클래스 의미적 분할 방법을 채택합니다.DeepLabV3+는 기존 DeepLabV3 아키텍처를 확장하여 인코더-디코더 구조를 추가한 것으로, 다양한 스케일에서 확장된 컨볼루션을 적용하여 멀티스케일 맥락 정보를 처리합니다.모델은 Keras 라이브러리를 기반으로 구축되며, ResNet50을 백본으로 사용하여 저수준의 특징과 DeepLabV3+의 인코더에서 생성된 고수준의 특징을 결합합니다. 인코더는 확장된 컨볼루션을 사용하여 멀티스케일 정보를 처리하고, 딜레이티드 스페이셜 파이라미드 풀링(DSPP)은 다양한 확장 비율에서 컨볼루션을 적용하여 특징을 합치는 데 사용됩니다.결과적으로, 이 모델은 객체 경계를 따라 세분화된 분할 결과를 제공합니다.모델의 디코더 부분은 인코더에서 추출한 특징을 업샘플링하고, 백본 네트워크에서 추출한 저수준 특징과 결합하여 정밀한 분할을 달성합니다. 최종 출력은 이미지의 각 픽셀에 대한 클래스 확률을 나타내는 다중 클래스 분류를 위한 컨볼루션 레이어를 통해 생성됩니다.해당 문서 링크입니다.https://keras.io/examples/vision/deeplabv3_plus/

역대 산불 감지 챌린지 레퍼런스
XPRIZE Wildfire산불을 종식시킬 수 있는 다양한 기술 개발의 일환으로 열린 딥러닝 기반 산불 감지 대회입니다. 4년간 진행되는 대회이며, 총 상금 11,000,000 달러가 걸려있습니다. 위성 사진 기반 산불 감지 트랙과, 자율적 산불 대응 트랙 두 가지로 이루어져 있으며, 각각 지향하는 바가 다릅니다. Alberta Wildfire Detection Challenge 2022Alberta Wildfire와 FPInnovations가 진행한 산불 감지 대회입니다. 다수의 기업이 참여하였으며, 최종 우승 모델은 Alberta Wildfire의 산불 감지 전략 기술로 인계되었습니다.
비식별화 데이터가 아님을 확인사살 해드립니다.
test image, mask의 데이터셋이 비식별화 하지 않았다는 증거를 첨부합니다. 첨부한 .csv 파일은 데이터셋을 직접 다운 받아 동일한 데이터가 있으면 적어둔 데이터입니다. 데이터 양이 많아 코드를 병렬적으로 실행시켜 탐색했습니다. 데이터는 여기서 다운 받을 수 있습니다.https://drive.google.com/drive/folders/1Z_YBaGT1XveTtfu51A4AlJf28aGlP-Srhttps://drive.google.com/drive/folders/1HD34RJMlRN-XZgNYTu3PBOJ2FYyQoOe4 <code class="language-plaintext">import numpy as np def are_images_identical(image1, image2): # 두 이미지의 형태가 같은지 확인 if image1.shape != image2.shape: return False # 각 픽셀별로 값이 동일한지 확인 comparison = image1 == image2 if comparison.all(): return True else: return False </code> 만약 데이터에 노이즈를 삽입한다거나 단순 채널 셔플만 했어도 다음 코드는 참이 나올 일은 없을 겁니다. “./test_img/" 에 있는 4,000장 모두 오픈 데이터셋에서 다운받을 수 있었고 저 코드를 통해 픽셀 숫자, 채널 순서까지 모두 동일함을 알 수 있습니다. 그에 대한 증거로 매칭되는 test_img와 test_mask를 정리해둔 .csv 파일을 첨부합니다. 참고로 0~3900번 데이터는 첫번째 링크, 3901~4000번 데이터는 두번째 링크에서 다운받으실 수 있으며데이터를 모두 다운받기 부담스러운 참가자분들은 두번째 링크에서 sample.zip 를 다운받고 비교해보실 수 있습니다.

"비식별화"는 데이터를 삭제, 대체, 범주화하여 유추할 수 없도록 처리하는 것을 뜻합니다.
원본의 파일명인 LC08_L1TP_072088_20200829_20200830_01_RT_Kumar-Roy_p00662.tif 을test_img_{i}.tif 로 바꾼것을 비식별화라고 하지는 않습니다. 아까 글의 예시로 train 데이터 이외에, 정답으로 제출해야할 test 데이터에 대한 정답도 하나 첨부하겠습니다. predict 해야하는 test_img_215.tif (png 버전) 원본 Oceania/z072088_masks/LC08_L1TP_072088_20200829_20200830_01_RT_Kumar-Roy_p00662.tif (png 버전) 마스킹된 정답 파일 데이터 깃허브 주소https://github.com/pereira-gha/activefire 정답 데이터 원본 다운로드는 아래 구글 드라이브 링크 https://drive.google.com/drive/folders/1Z_YBaGT1XveTtfu51A4AlJf28aGlP-Sr
AIFactory 너무 안 좋게 보지는 마세요.
AI Factory가 뭐했길래 탈퇴하니 마니 대회 마지막 날에 흐름을 끊으시나요. 총 상금 1600만원 대회인데 오픈 데이터셋을 쓰기라도 했나요? 심지어 오픈 데이터 셋에 특정 post-process를 하지 않고 그대로 가져오기라도 했나요? 2시간 마다 제출이라는 디버프 없이 팀 자체 무한 제출을 해볼 수 있는 사람들이랑 경쟁을 하기라도 했나요? mIoU 계산 코드가 잘못됐다는 사실을 알고도 공지사항 없이 묵과하고 개인 답변으로만 0, 1로만 제출한 .pkl 파일만 인정한다 했나요? threshold 실험을 이진 탐색을 해 짧은 시간 내에 global한 threshold 찾는 노가다 없이 오픈 데이터셋을 다운받고 자체적 평가를 할 수 있었나요? 치팅한 사람들을 제대로 걸러는 방법이 명확하게 없기라도 하나요? 마지막 날까지 꾸역꾸역 팀 병합 안 하다가 대회 종료 직전에 병합하는 꼼수를 막지 못하기라도 했나요? 아무튼 AI Factory는 잘못이 없습니다.참가자 여러분 몇 주 동안 고생 많으셨습니다.

제 6회 spark 챌린지 대회 규칙 및 앞으로의 대회 진행에 대한 고찰
반갑습니다. Spark 챌린지 5회 우승자 안보이닝입니다. 이번 6회 Spark 챌린지에도 관심이 있어 참가를 하였지만, 대회 규칙과 더불어 문제 될 수 있는 부분이 많은 것 같습니다. 해당 부분을 종합적으로 검토하여, 다음 대회에 있어서 더 엄밀한 규칙과 환경을 구축하여 공정한 경쟁이 될 수 있으면 하는 마음에 글을 작성합니다. 우선, 대회 마감일까지 수고하신 대회 참가자분들 모두 수고가 많으셨습니다. 크게 두가지로, 대회 평가 산식 및 Dataset leakage 에 대해 다뤄보겠습니다. 1. 대회 평가 산식 MIOU 바로 본론으로 대회 규칙에 대해 다시 짚어보겠습니다.다음 규칙과 같이 mask 된 부분의 값이 uint8 로 이루어진 0 또는 1의 값이여야합니다.또한, 대회 규정의 평가 산식인 MIOU에 대한 서술은 다음과 같았습니다.원래 산식대로라면, MIOU = [ TP / ( FN + TP + FP) ] 를 만족하는 “픽셀 수”를 계산하는 것이 정상입니다.이번 대회에서는 오류를 디버깅을 할 수 있도록 에러 문구를 리턴해주지만, uint8 을 만족하는 pkl 파일은 전부 에러 문구 없이 제출이 가능했고, "픽셀 수"가 아닌 “value” 값으로 산식이 되었던 것 같습니다. 예측했지만 실제로는 음성 값인 FP의 값의 영향을 줄여주기 위해 threshold 값을 평소보다 조금 높인 상태에서, uint8 의 값의 범위는 0 ~ 255이므로, 예측을 못했던 실제 양성 값인 FN의 영향을 줄여주기 위해 mask 된 값의 value 를 1이 아닌 255로 산출하면 MIOU 에서 TP 의 영향이 지배적으로 커지게 됩니다. 결국 MIOU에서 [ 255 * TP / 255 * TP + α ]의 값을 가지게 되므로, α의 영향력이 매우 적어지기 때문에 MIOU 가 거의 1에 근접하게 나올 수 있습니다. 물론 255가 아니더라도, 1이 아닌 적당한 값의 uint8 값으로 바꾸어 점수를 조금 더 낼 수도 있었을테고, 아마 리더보드에 생각보다 많이 존재할 것으로 예상됩니다. 2. Dataset Leakage 우선, 저는 이번 대회의 훈련 데이터셋과 정답 데이터셋을 별도로 이미 확보하고, 실제로 일치하는것을 확인하였습니다. 본 대회의 dataset 은 특정 데이터셋을 가공하지않고 “그대로” 사용하였음을 먼저 밝힙니다. (단편적인 하나의 예시입니다. 아직 대회가 종료되지 않아 링크나 파일을 공유하지는 않겠습니다만, LC08_L1TP_049066_20200812_20200813_01_RT_p00700.tif 라는 파일의 tif를 png로 변환한 사진은 train_10073.tif 를 png로 변환한 사진과 동일합니다.) 물론, 훈련 자체를 해당 데이터를 이용하는 것은 규칙에 위배되겠지만, 이번 대회에서 threshold 값을 설정하는 것은 허용되었습니다. 이를 이용하여 해당 정답 데이터셋을 활용하여 최적의 threshold값을 각 test할 이미지마다 개별적으로 설정한다던가, 혹은 global 하게 적용했을때 가장 높은 점수가 나오는 threshold가 몇인지 리더보드에 직접 제출해보지않고 추적이 가능합니다. 또한, 자체 리더보드를 만들어 제출 시간의 제한을 두지않고 실시간으로 모델의 성능을 평가할 수 있게됩니다. 종합적으로, 해당 대회의 수상자 및 검토를 하는 과정이 결코 쉽지는 않아보입니다. 물론, 이번 대회에서도 최대한 공정한 경쟁을 위해 힘을 써주셨지만, 해당 사항을 바탕으로 다음 7회 대회 때는 더욱 공정한 경쟁을 할 수 있도록 조금 더 힘을 써주셨으면 좋겠습니다. 감사합니다 :)

scikit-image를 활용한 데이터 증강
앞선 토론에서 데이터 증강의 장점과 여러 방법들에 대해서 공유해주신 내용이 있었습니다.이번 대회에서는 어떻게 해당 내용을 적용할 수 있을 지에 대한 방법을 공유하고자 합니다. 우선 제공된 train image는 아래와 같이 위성 이미지와 mask 이미지로 구분되어 있습니다.위성 데이터만 봤을 때는 많은 정보를 얻기 어려워 보이지만, mask 이미지를 자세히 보면 작게 masking 처리가 되어있는 부분을 볼 수 가 있습니다. 제공된 dataset 이외에 외부 data를 활용할 수 없기 때문에 주어진 data를 augmentation하는 것이 필요하다 판단하였습니다.많은 방법들 중 mask 정보를 유지하면서 augmentation을 하기 위해 90도로 회전을 시키는 방법을 적용하였습니다. baseline 코드가 ndarray 형태로 이미지를 다루기 때문에, scikit-image (https://scikit-image.org/)를 사용하였습니다. skimage.transform.rotate(image, angle, resize=False, center=None, order=None, mode='constant', cval=0, clip=True, preserve_range=False)해당 package의 tranform.rotate 함수를 활용하여 이미지 데이터를 회전하였습니다.img2 = transform.rotate(img, angle=90, resize=False) 위성 이미지와 같이 mask 데이터도 동시에 회전을 시켜 데이터 증강을 적용할 수 있습니다.
Image segmentation이란?
Image Segmentation의 정의머신러닝에서 Image segmentation이란 데이터를 개별 그룹으로 분리하는 프로세스를 의미. Deep learning에서 Image segmentation은 label이나 범주를 이미지의 모든 픽셀과 연결하는 segement map을 만드는 과정이 중요ex. 물체의 경계를 윤곽선으로 표시하여 해당 object, 물체가 있는 위치 찾아내기, 개별 object detection부터 이미지 속 여러 영역에 개별 레이블 지정 Image segmentation의 종류1. Semantic Segmentation입력된 이미지의 모든 단일 픽셀에 해당 콘텐츠를 설명하는 클래스 레이블을 할당하는 것Supervised learning(지도 학습)과 Unsupervised learning(비지도 학습)으로 나뉨지도 학습의 경우, 수동으로 semantic label을 붙인 이미지 데이터셋을 모델에 훈련시킨 후 작업 수행비지도 학습의 경우, semantic label이 지정된 이미지 데이터셋 불필요. 다양한 방법을 통해 사전 지식 없이도 이미지의 레이블을 학습하는 방식Image classification 모델의 수정을 통해 구현! ➡ FCN(완전 컨볼루션 네트워크)에서 시작됨 ➡ DeepLab, FastFCN, DeepLabV3, Transformer-based models 등의 모델2. Instance Segmentation이미지의 개별 객체를 식별하고 분할. 이미지의 각 객체에 고유한 레이블을 할당하고, 각 객체의 경계 또한 식별 가능객체의 모양이나 컨텍스트에 따라 이미지의 개별 객체를 식별 및 세분화일반적으로 Mask R-CNN Architecture 모델을 기반으로 제작구현 방식 1. Bottom-up 방식 : 이미지의 개별 픽셀을 감지하는 것부터 시작해 이러한 픽셀을 함께 그룹화하여 객체 형성구현 방식 2. Top-down 방식 : 이미지의 전체 장면을 감지하고 개별 객체를 식별한 뒤 세그먼트화3. Panoptic Segmentation단순히 객체를 구별하는 semantic segmentation과 객체의 경계를 이해하는 instance segmentation의 개념을 병합한 모델이미지의 개별 객체를 식별하고 세분화 + 장면의 의미적 내용 식별semantic&instance segmentation이 상호 보완적이라는 원칙에 기반semantic segmentation을 통해 장면의 시맨틱 의미적 내용 식별instance segmentation을 통해 장면의 개별 객체를 식별 및 세분화출력에 물건과 사물을 모두 포함하여 정확하게 표현하며, 셀 수 있는 대상(ex. 차량, 사람, 나무 등)과 셀 수 없는 대상(도로, 하늘 등)을 표현 Image segmentation의 구조와 원리1. Recognition + LocalizationImage segmentaion 모델은 먼저 이미지에서 특징을 추출하여 객체를 인식(Recognition)하고 위치를 파악(Localization)한다. 여기서 추출하는 특징은 색상이나 텍스처, 모양 등이 있다. Image segmentation에 사용되는 모델은 이러한 feature 정보를 사용해 이미지를 부분적으로 구성하고, segment map을 만들어 픽셀 단위의 경계를 기준으로 정보를 정의한다.Recognition : 이미지가 segment화되면 모델은 각 세그먼트를 객체 또는 배경으로 분류한다. 이 작업은 이미지에 포함된 객체로, 레이블이 지정된 이미지 데이터셋에 대해 학습한 Classification 기능을 사용해 수행한다.Localization : 마지막으로 모델은 객체 주변의 bounding box(경계 상자)를 식별하여 객체의 위치를 찾는다. 경계 상자는 객체의 경계를 정의하는 4개의 좌표 집합을 의미한다 2. Encoder + Decoder컴퓨터 비전 분야에서 대부분의 image segmentation model은 Encoder-Decoder 구조로 구성된다. Decoder로부터 나온 segment map은 이미지에서 각 개체의 위치를 나타내는 일종의 지도이다.Encoder : 점점 더 좁고 깊어지는 일련의 필터를 통해 이미지를 추출하는 레이어. 입력된 정보를 취합/저장하는 역할. 주로 컨볼루션과 풀링과 같은 연산을 사용해 입력 데이터의 추상화된 특징을 추출하고 이를 저차원의 표현으로 변환.Decoder : 인코더의 출력을 입력 이미지의 픽셀 해상도와 유사한 세분화 마스크로 확장시키는 레이어 마스크. 인코더로부터 축약된 정보들을 풀어서 반환/생성해주는 역할. 주로 업샘플링과 같은 연산을 사용하여 저차원의 표현을 다시 고해상도의 출력으로 확장

mask R-cnn 이란? (vs Faster R-CNN)
● mask r-cnn?- Mask R-CNN은 객체 탐지(Object Detection)와 인스턴스 분할(Instance Segmentation)을 동시에 수행할 수 있는 강력한 딥러닝 모델.-Faster R-CNN을 기반으로 확장된 형태이다. 하지만 Faster R-CNN은 이미지 내 객체의 위치를 박스로 표현하는 반면, Mask R-CNN은 각 객체에 대한 픽셀 수준의 정밀한 마스크를 추가로 제공합니다. 이를 통해 객체의 정확한 형태와 경계를 파악할 수 있습니다.Mask R-CNN에 대해 간단한 구조 설명과 핵심적인 내용만 추려서 설명드리겠습니다.(Reference:https://arxiv.org/pdf/1703.06870.pdf) ● mask r-cnn 구조 입력 이미지: 여러 사람이 축구를 하는 장면의 이미지가 모델의 입력으로 사용됩니다.Feature Extraction: 이미지는 컨볼루션 신경망(conv layers)을 통과하여 특징을 추출합니다. 이 단계는 이미지로부터 유의미한 정보를 추출하는 데 사용됩니다.Region Proposal Network (RPN): 추출된 특징 맵 위에서 작동하여, 객체가 있을 것으로 추정되는 영역을 제안합니다.RoIAlign: RPN에서 제안된 영역을 정밀하게 추출하기 위해 RoIAlign 기술을 사용합니다. 이는 픽셀 수준에서의 정밀한 정렬을 가능하게 해서, 객체의 경계를 더욱 세밀하게 분할할 수 있도록 합니다.분류 및 박스 회귀: 제안된 각 영역에 대해 객체의 클래스를 분류하고, 객체의 위치를 더 정확히 특정하기 위해 박스 회귀를 수행합니다.마스크 생성: 마지막으로, 객체의 정확한 픽셀 수준의 형태를 분할하는 마스크를 생성합니다. 이 마스크는 객체의 형태를 픽셀 단위로 정확히 나타냅니다.이 구조를 보시면 이미지는 객체가 클래스별로 표시된 분활 마스크를 보여주는것을 확인할 수 있습니다. 예를들면 사람들 각각이 다른색으로 구분되어 표시됩니다. 이는 Mask R-CNN이 이미지내에서 개별 객체를 정확히 식별하고 각 인스턴스에 대한 정밀한 마스크를 제공할 수 있음을 나타냅니다. 이 프레임 워크는 각 객체의 클래스를 분류하고 위를 정확히 예측하며 모양을 정확하게 분활하는데 탁월한 성능을 보인다고 합니다. ● Faster R-CNN 구조 -Faster R_CNN 은 backbone을 통해 얻은 feature map 을 RPN에 입력한 후 ROI를 얻습니다. 이를 RoI Pooling에 넣은 후 얻은 고정된 크기의 feature map 을 통해 fc layer에 입력합니다. 이후 Classification branch 와 bounding box regression branch 에 입력해 class label 과 bounding box offset 을 예측하게 됩니다. Loss function loss function은 Lcls+ Lbox 까지 fast R-CNN mask R-CNN 두 모델 모두 동일 합니다. 하지만 mask R-CNN 은 Lmask 가 더해지고 이것은 mask 에 대한 loss 로 binary cross entropy loss 입니다. mask branch 에서 추출한 km^2 크기의 feature map 의 각 cell에 sigmoid function을 적용한 후 loss를 구합니다. RoIAlign? (RoI?)-Region of interest(ROI): 컴퓨터 비전에서 이미지 또는 비디오 내에서 주목해야 할, 분석하고자 하는 특정부분을 지칭합니다. 객체 탐지, 분활, 분류 와 같은 작업에서 ROI는 알고리즘이 초점을 맞추어야 하는 이미지 내의 영역을 정의합니다.-RoI 의 중요성: ROI를 식별함 으로서 알고리즘이 처리해야 하는 데이터 양을 줄이고 중요한 부분에만 집중할 수 있습니다. 또한 특정영역에 초점을 맞춤으로써 알고리즘이 배경 잡음이나 관련 없는 정보의 영향을 덜 받고 객체 탐지나 분류 등의 작업에서 더 정확한 결과를 얻을 수 있습니다.-RoI pooling : fast r-cnn 에서 도입된 방법으로 각 Rol를 고정된 크기의 특성 맵으로 변환합니다. 이는 후속 분류기와 동일한 입력 크기를 가질 수 있도록 보장합니다.-Rol pooling 문제점 : 원본 Rol 크기나 비율이 고정된 그리드 크기와 정확히 일치하지 않을 경우, 그리드 셀에 매핑하기 위해 Rol 을 양자화 해야합니다 . 그 과정에서 Rol 의 위치정보가 일부 손실되거나 왜곡될 수 있습니다. 또한 각 그리드 셀 내에서 최대 값을 선택하므로 해당 셀의 다른 픽셀 정보는 무시되므로 세부적인 위치정보나 경계정보가 손실 될 수 있습니다. 특히 인스턴스 분활과 같이 정밀한 객체 경계정보가 중요한 작업에서 이러한 손실은 성능 저하로 이어질 수 있습니다. -ROlAlign: Rol pooling의 문제점들을 해결하기 위해 개발 되었고 RolAlign의 주요차별점은 양자화 단계를 거치지않고 관심영역의 정확한 픽셀 값들을 직접 사용하여 특성을 추출한다는 점입니다. 이를 위해 RolAlign 은 다음과 같은 접근 방식을 사용합니다.Billinear interpolation(양선형 보간): RolAlign은 각 Rol 를 고정된 크기의 그리드로 나누고 이 그리드의 각 샘플링 포인트에서 특성맵의 값을 양선형 보간을 사용하여 계산합니다.양선형 보간은 주변 4개의 픽셀 값들을 기반으로 샘플링 포인트의 값을 추정하는 방법이며 이를 통해 보다 정밀한 특성 값을 얻을 수 있습니다.양자화 오류 제거: RoIAlign은 양자화 과정 없이 직접 샘플링 포인트를 계산합니다. 이로써 RoI의 위치 정보가 보다 정확하게 유지되며, 객체의 세밀한 경계 정보도 더 잘 포착할 수 있습니다. Experiments: Instance Segmentation-Main Result Mask R-CNN이 state of the art 모델 보다 훨씬 우수한 성능을 보였습니다.depth 가 깊을 수록 성능이 좋게나왔습니다.Rolpool Rolwarp를 사용한 것보다 RolAlign 을 사용하여 더 높은 성능을 보였습니다. Mask R-CNN의 고도화된 인스턴스 분할 능력은 특히 위성사진을 통한 산불 감지와 같은 고정밀 모델링 작업에 있어 매우 중요한 역할을 합니다. 이 모델은 RoIAlign 기법을 통해 세밀한 위치 정보와 객체 경계를 정확히 포착함으로써, 단순히 산불이 발생한 영역을 탐지하는 것을 넘어, 화재의 정확한 범위와 형태를 픽셀 단위로 분할해 낼 수 있는 능력을 제공합니다. 또한, Mask R-CNN은 다양한 크기와 형태의 산불을 정확히 식별할 수 있어, 광범위한 지형과 다양한 화재 상황에 대응하는 데 있어 뛰어난 유연성을 보일것으로 생각합니다. 이처럼 Mask R-CNN의 고정밀 인스턴스 분할 기능은 위성사진을 활용한 산불 감지 모델을 구축하는 데 있어 핵심적인 기술로서, 효율적이고 효과적인 모델이 될 것 입니다.

학습 데이터 증강
데이터 증강(augmentation)은 기존의 학습 데이터를 변형하거나 확장하여 모델이 더 다양한 상황에서 더 잘 일반화되도록 하는 기술입니다. 데이터 증강은 다음과 같은 이점들을 제공합니다:다양성 확보: 모델이 다양한 상황에 대해 학습할 수록 일반화 능력이 향상됩니다. 데이터 증강을 통해 다양한 조건에서 촬영된 이미지를 만들어내므로, 모델은 다양한 환경에서도 더 나은 성능을 발휘할 수 있습니다.과적합 방지: 모델이 학습 데이터에 너무 맞추어져서 새로운 데이터에 대한 일반화 능력이 떨어지는 과적합을 방지할 수 있습니다. 데이터 증강은 모델이 학습 데이터의 미묘한 변화에 민감하게 반응하는 것을 방지하여 일반화 능력을 향상시킵니다.데이터 부족 보완: 특히 딥러닝 모델을 학습시킬 때 데이터가 부족한 경우가 많습니다. 데이터 증강을 통해 원래 데이터셋을 확장함으로써 이러한 문제를 완화할 수 있습니다.데이터 불균형 해결: 일부 클래스나 카테고리의 데이터가 부족한 경우, 데이터 증강을 통해 클래스 간 균형을 맞출 수 있습니다. 데이터 증강의 대표적인 접근법들은 아래와 같습니다.이동 (Translation) 및 회전 (Rotation)이미지를 랜덤하게 이동하고 회전시켜 데이터를 다양하게 만듭니다.이는 실제 환경에서 다양한 각도 및 위치에서 촬영된 이미지를 모방합니다. 확대 및 축소 (Scaling)이미지를 랜덤하게 확대하거나 축소하여 다양성을 추가합니다.다양한 거리에서 촬영된 이미지에 대한 학습을 강화합니다. 반전 (Flipping)이미지를 수평 또는 수직으로 반전시켜 데이터를 증강시킵니다.대상의 형태나 위치에 대한 변화를 학습할 수 있습니다. 원근 변환 (Perspective Transformation)이미지를 랜덤하게 원근 변환하여 다양한 시각에서의 대상을 학습합니다.지형과의 상호작용을 모방하여 모델의 강인성을 향상시킵니다.

ViT와 CNN 기반 모델의 차이
“Do Vision Transformers See Like Convolutional Neural Networks?” 내용에 기반합니다.https://arxiv.org/abs/2108.08810 ViT(VisionTransformer)가 만들어진 이후 ViT의 성능이 기존 CNN 모델들을 앞서게 되었고,왜 그런지 ViT와 ResNet의 차이를 보이며 설명합니다 각 모델이 어떻게 학습하는지 알아보기 위해 Neraul Network Representation Similarity를 분석하며,이 분석은 Centered Kernel Alignment(CKA)를 통해 이뤄집니다. CKA를 수행하기 위해 X와 Y를 입력 받습니다. X와 Y는 Activation 행렬로 한 Layer의 표현을 의미합니다. 이때, X와 Y는 아래 그림과 같은 크기를 같습니다. m은 비교 샘플의 개수를 의미합니다. 그리고 p1과 p2는 각각 X와 Y에 속해 있는 뉴런의 개수를 의미합니다.X와 Y를 준비했다면, X와 Y를 사용해서 Gram 행렬을 만듭니다. 만드는 방식은 아래와 같습니다.Gram 행렬을 통해 각 데이터 샘플 사이에 존재하는 Layer의 표현력을 비교할 수 있습니다. 예를 들어, L은 Y안에 속해있는 m개의 데이터 샘플 간의 표현을 비교하는 데 사용할 수 있게 됩니다.그럼 이제 CKA를 어떻게 구하는지 살펴보겠습니다. CKA는 아래와 같이 계산할 수 있습니다. 아래 식에서 HSIC는 Hilbert-Schimidt Independence Criterion입니다. HSIC는 두 변수 사이의 연관성을 계산하는 데 사용되는 통계학 기술입니다. 즉, HCIC(K, L)은 K와 L사이에 연관성을 계산하는 데 사용되는 것입니다. ViT와 ResNet의 각 Layer들이 학습하는 것의 차이아래 그림은 ViT와 ResNet에 있는 모든 Layer X, Y 쌍에 CKA를 계산한 Heatmap입니다.ViT는 모든 Layer에 걸쳐서 CKA 유사도가 비슷합니다.ResNet은 낮은 Layer와 높은 Layer 간에 차이가 존재하는 것으로 보입니다. 위 그림을 보면, Layer가 낮은 부분과 높은 부분으로 나뉘는 것처럼 보입니다. 다음에서는 X는 ViT의 모든 Layer에서 가져오고, Y는 ResNet의 모든 Layer에서 가져온 CKA 결과입니다.ResNet의 [0%, 50%] 구간에 있는 Layer들은 ViT의 [0%, 25%] 정도의 Layer들과 유사합니다. 비슷한 것들을 학습하는 데 있어서, ViT보다 ResNet이 더 많은 비율의 Layer가 필요하다고 볼 수 있습니다.ResNet의 나머지 절반 정도의 Layer들은 ViT의 [25%, 50%] 구간에 있는 Layer들과 유사합니다.ViT의 [66%, 100%] Layer들은 ResNet의 모든 Layer들과 유사하지 않습니다. ViT의 해당 Layer는 Classification Token의 표현을 학습하는 데 집중해서 그럴 수 있다고 논문에서 주장합니다. 지금까지 실행한 두 가지 실험 결과를 종합하면 아래와 같은 결론을 내릴 수 있습니다.ViT의 낮은 Layer들과 ResNet의 낮은 Layer들은 서로 다른 표현들을 학습합니다. (ViT는 전 Layer에 걸쳐서 비슷한 걸 학습합니다. 반면, ResNet은 아닙니다.)ViT는 더 낮은 Layer들에서 높은 Layer로 더 강하게 신호들을 전파합니다.ViT의 마지막 부분의 Layer들은 ResNet의 모든 Layer와 상당히 다른 표현들을 학습합니다. 원본: https://medium.com/@parkie0517/do-vits-see-like-cnns-fb61a5e815b4

[논문리뷰] - SegFormer
SegFormer : Simple and Efficient Design for Semantic Segmentation with Transformers 본 대회에 적용할 수 있는 논문을 찾다가 적용 사례도 있고 괜찮아 보여서 공유합니다. SegFormer는 Transformer를 Semantic Segentation task에 적용한 모델입니다. 특징SegFormer는 multscale feature를 뽑는 계층적인 구조의 Transformer encoder로 구성됩니다. 특이하게 positional encoding이 필요없도록하여 이에 따라 학습에 사용되지 않은 이미지 사이즈를 테스트시에 사용했을 때 interpolation 사용으로 인한 성능 하락을 피할 수 있었다고 합니다.복잡한 decoder를 고려하지 않고 MLP로만 이루어진 MLP decoder를 사용하였다. encoder에서 얻은 multiscale feature를 결합하여 각 feature map에서의 local attention과 합쳐진 feature map에서의 global attention을 통해 powerful한 representation을 얻었다고 합니다. Paper — https://arxiv.org/abs/2105.15203Code - https://github.com/visionhong/Vision/blob/master/Semantic_Segmentation/SegFormer/segformer.py
Pre-trained model 추천 및 fine-tuning 전략 소개
이번 글로벌 산불 감지 챌린지는 위성 이미지 데이터를 활용하여 실시간으로 산불을 감시하고 조기에 탐지하기 위한 인공지능 기반의 솔루션 개발을 목표로 합니다. 본 토론에서는 사전 학습된 모델의 사용과 미세조정(fine-tuning) 전략, 그리고 이러한 접근 방법이 산불 감지 및 분류 문제에 어떻게 최적화될 수 있는지 논의하고자 합니다. 대회 규정에 따르면, Global COCO 데이터셋으로 사전 학습된 가중치는 사용할 수 있으나, 산불 판단을 위해 특별히 제작된 모델의 가중치 사용은 금지됩니다. 이러한 조건 하에서, 성능이 뛰어난 사전 학습 모델 두 가지를 추천합니다: EfficientNetB7: EfficientNet은 다양한 크기의 이미지에 대한 효율적인 학습을 가능하게 하는 스케일링 방식을 제시합니다. 특히 B7 버전은 높은 정확도를 제공하면서도 상대적으로 적은 계산 비용으로 운영됩니다. 이 모델은 다양한 이미지 인식 작업에서 뛰어난 성능을 보여줄 뿐만 아니라, 위성 이미지의 복잡한 패턴과 산불의 세밀한 특성을 탐지하는 데 유리합니다.참고 코드https://www.tensorflow.org/api_docs/python/tf/keras/applications/efficientnet/EfficientNetB7https://pytorch.org/vision/main/models/generated/torchvision.models.efficientnet_b7.html DeepLabV3+: DeepLab 시리즈는 Semantic Segmentation 문제에 특화된 구조를 가지고 있으며, V3+ 버전은 atrous convolution과 Spatial Pyramid Pooling을 통해 다양한 스케일의 객체를 더 잘 인식할 수 있습니다. 위성 이미지에서 산불 영역을 정확하게 구분해내는 데 이 모델이 특히 유용합니다.참고 코드https://github.com/VainF/DeepLabV3Plus-Pytorch 다음은 fine-tuning을 위한 전략 소개로, 조금 일반적이지만, 위의 모델들을 산불 데이터에 맞게 tuning 하는 과정에서 사용할 수 있는 여러 전략입니다. 모델의 성능을 높이실 때 참고하면 좋고, 더 좋은 tuning 방법들은 댓글로 달아주시길 바랍니다.재현성 보장을 위한 Seed 고정: 모델 학습 과정에서의 재현성을 보장하기 위해 난수 생성 시드를 고정합니다. 이는 모델 초기화, 데이터셋 분할, 그리고 학습 과정에서 발생할 수 있는 모든 난수 생성에 적용됩니다. 고정된 시드 값은 실험 결과의 비교 가능성과 검증 과정의 신뢰도를 높여줍니다. Learning Rate Scheduling: 학습률(Learning Rate)은 학습 과정에서 매우 중요한 하이퍼파라미터입니다. 초기에는 큰 학습률을 설정하여 빠른 수렴을 유도하고, 학습이 진행됨에 따라 점진적으로 학습률을 감소시키는 스케줄링을 적용합니다. 이 방법은 모델이 더 세밀하게 최적화될 수 있도록 돕습니다. Data Augmentation: 위성 이미지의 다양성을 인위적으로 증가시키는 것은 모델이 산불 영역을 더 강건하게 인식하는 데 도움이 됩니다. 회전, 확대/축소, 수평/수직 반전 등의 데이터 증강 기법을 사용하여, 모델이 다양한 각도와 조건에서의 산불 이미지에 대해 더 잘 일반화될 수 있도록 합니다. Transfer Learning 깊이 조정: 사전 학습된 모델을 미세 조정할 때, 전체 모델을 한꺼번에 학습시키는 대신, 모델의 마지막 몇 층만을 학습 대상으로 설정할 수 있습니다. 초기 층은 일반적인 이미지 특성을 캡처하는 데 유용한 반면, 마지막 층은 특정 작업(예: 산불 감지)에 더 관련이 깊습니다. 이를 통해, 모델이 새로운 데이터셋에 더 효과적으로 적응하도록 할 수 있습니다. Regularization Techniques: 과적합을 방지하기 위해 드롭아웃(Dropout), L1/L2 정규화 등의 기법을 적용할 수 있습니다. 이는 모델이 학습 데이터에만 과도하게 최적화되는 것을 방지하고, 일반화 성능을 향상시키는 데 도움이 됩니다. Evaluation Metric 선택과 최적화: 산불 감지 문제에서는 정확도뿐만 아니라, 재현율(Recall)과 정밀도(Precision)와 같은 지표가 중요합니다. 산불 감지 시스템에서는 놓치는 것보다 오경보를 줄이는 것이 더 중요할 수 있으므로, 이러한 지표들을 균형 있게 고려하여 모델을 최적화합니다. 이미지 출처https://www.researchgate.net/figure/Efficientnetb7-model-architecture-25_fig4_357488896https://paperswithcode.com/lib/detectron2/deeplabv3-1

U-net 모델 분석
U-net U-Net은 의료 영상 분야에서 뛰어난 성능을 보인 딥러닝 모델이다. 이 모델은 End-to-End, Fully-Convolutional Network(FCN) 기반의 구조로, 오토인코더 형태인 인코더와 디코더 기반 설계를 특징으로 한다. 인코더 부분은 입력 이미지로부터 컨텍스트 정보를 추출하며, 이 과정에는 전형적인 Convolution network 및 max pooling layer가 사용된다. 결과적으로, 이미지의 차원이 축소되는 반면, feature 깊이는 증가한다.디코더는 인코더로부터 얻은 컨텍스트 정보를 활용해 타겟 이미지의 각 픽셀에 대한 레이블을 세밀하게 예측한다. 이때, Up-sampling layer를 통해 이미지의 차원을 단계적으로 확장하며, 인코더로부터 전달받은 feature 맵과의 결합을 통해 보다 정밀한 segmentation을 한다.U-net은 인코딩 단계에서 각 레이어로부터 얻은 feature을 디코딩 단계의 각 레이어와 결합하는 방법을 사용한다. 이러한 인코더 레이어와 디코더 레이어와의 스킵 연결을 기준으로 좌우가 대칭이 되도록 레이어를 배치하여 U자 형태로 구성하여 전체 network를 통해 이미지의 컨텍스트 정보와 정확한 localization을 동시에 처리할 수 있다.