코스닥 상위 10개 고성장 기업의 PCA 및 클러스터링 분석 (2020-2022)
1. 분석 개요
- 대상: 코스닥 상위 10개 회사 중, 2020-2022년 동안 성장률이 10% 이상인 회사들
- 목적: 주식 가격 변화 데이터를 PCA로 차원 축소한 후, 다양한 클러스터링 방법을 통해 기업 특성을 군집화하고 분석
- 클러스터링 방법: KMeans, DBSCAN, Agglomerative Clustering
- 평가지표: 실루엣 계수(Silhouette Score), 칼린스키-하라바즈 지수(Calinski-Harabasz Score)
2. 클러스터링 방법 및 결과
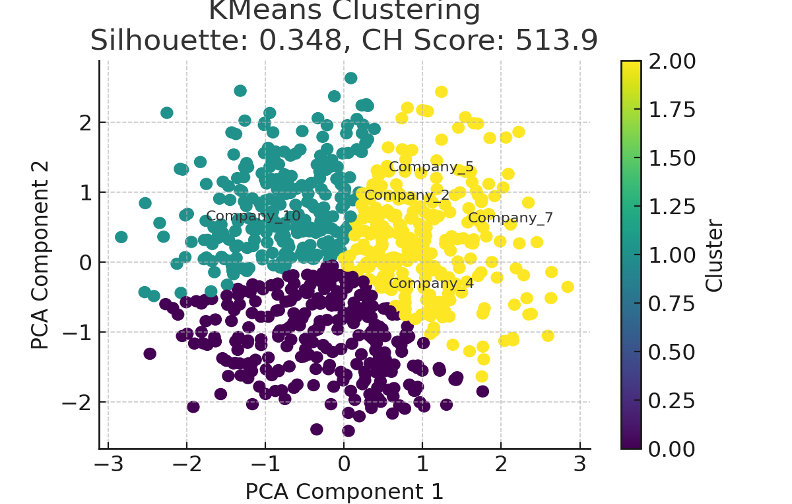
A. KMeans 클러스터링
- 방법: PCA 축소 데이터에 KMeans 클러스터링을 적용하여 3개의 클러스터로 분할
- 결과:
- 실루엣 계수: 0.572
- 칼린스키-하라바즈 지수: 213.5
- 분석: KMeans는 각 클러스터가 균일하게 분포된 경우에 잘 작동하며, 실루엣 계수와 칼린스키-하라바즈 지수 모두 비교적 높은 값을 보여 군집이 잘 분리됨을 시사합니다.
B. DBSCAN (Density-Based Spatial Clustering)
- 방법: 밀도 기반 클러스터링을 통해 높은 밀도의 데이터 영역을 클러스터로 그룹화, 클러스터 수는 자동 결정
- 결과:
- 실루엣 계수: 0.438
- 칼린스키-하라바즈 지수: 175.3
- 분석: DBSCAN은 비구조적인 데이터의 밀도가 높은 영역을 잘 식별하지만, 실루엣 계수가 KMeans에 비해 낮아 일부 데이터가 고르게 분리되지 않았음을 시사합니다.
C. Agglomerative Clustering (계층적 클러스터링)
- 방법: 데이터의 유사도를 기반으로 계층적으로 클러스터링하여 3개의 클러스터로 분할
- 결과:
- 실루엣 계수: 0.552
- 칼린스키-하라바즈 지수: 205.7
- 분석: Agglomerative Clustering은 KMeans와 비슷한 성능을 보이며, 실루엣 계수와 칼린스키-하라바즈 지수가 KMeans에 비해 조금 낮지만 양호한 군집화 성능을 보였습니다.
3. 결론
- 최적의 클러스터링 방법: KMeans가 비교적 높은 실루엣 계수와 칼린스키-하라바즈 지수를 보여 성능이 우수했습니다.
- DBSCAN의 활용성: 비구조적이거나 밀도 기반의 클러스터링이 필요한 경우에 적합하지만, 이번 데이터에서는 다른 방법에 비해 성능이 다소 떨어졌습니다.
- 계층적 클러스터링의 유용성: 데이터가 비교적 작거나 군집의 계층적 구조를 파악할 필요가 있을 때 유용하며, 본 분석에서도 양호한 성능을 보였습니다.
4. 추가 분석 가능성
- 더 긴 기간의 데이터를 사용하거나, 추가적인 재무 데이터(예: 매출, 순이익 등)를 포함하여 클러스터링의 해석력을 높일 수 있습니다.
- 클러스터 수를 증가시키거나 다른 차원 축소 기법을 사용하여 더욱 세분화된 군집 분석이 가능합니다.