다양한 주제에 대해 논의하거나 지식을 공유합니다.
총 4242개

인공지능팩토리, ‘STK 2026’ 전시회 참여 성료
인공지능팩토리가 지난 6월 10일(수)부터 12일(금)까지 서울 코엑스(COEX)에서 개최된 'STK 2026' 전시회 참여를 마무리하였습니다. 바쁘신 일정 중에도 인공지능팩토리 부스(A101)를 찾아주시고 관심을 가져주신 모든 방문객 여러분께 감사의 말씀을 전합니다. 이번 전시회에서 인공지능팩토리는 공공기관 및 기업의 보안과 업무 환경에 특화된 아래 두 가지 핵심 라인업을 현장에서 선보였습니다.어시웍스(AssiWorks): 개발자 없이 툴 등록, 에이전트 구성, 워크플로우 자동화를 끝내는 노코드 플랫폼 (내부망/폐쇄망 온프레미스 구축 지원)어시루프(AssiLoop): 데이터 유출 없는 독립된 격리 환경에서 스스로 코드를 짜고 보고서를 완성하는 자율 실행형 에이전트 (한글 문서 .hwpx 업로드 지원) 현장에서 직접 뵙고 기관 및 기업의 보안 정책에 맞춘 전용 AI 에이전트 기술에 대해 이야기를 나눌 수 있어 뜻깊은 시간이었습니다.부스를 방문해 주신 분들께 다시 한번 감사드리며, 앞으로도 인공지능팩토리의 행보에 많은 관심 부탁드립니다. 감사합니다.
AIFactory_PR
0

2026 스마트농업 AI 경진대회
🏆2026 스마트농업 AI 경진대회🏆 농업이나 AI에 관심 있으신가요?좋은 공모전이나 경진대회를 찾고 계신가요?그렇다면 정답은 바로 여기! 🏆2026 스마트농업 AI 경진대회🏆3인~10인의 최고의 팀을 이루어총상금 1억원, 농림축산식품부장관상에 도전해 보세요! 📣 예선딸기 데이터를 활용한원격 작물재배 모델 개발 📢 본선개발 모델을 적용한스마트팜 원격 딸기 재배 실증 📅경진대회 일정- 6월 29일(월)까지 참가 신청&모집- 7월에 펼쳐지는 조별 문제해결 방식의 해커톤- 온라인 테스트 및 발표평가로 진행되는 예선- 2026년 9월~2027년 2월 개발 모델을 실제 온실 현장에 적용, 딸기 재배 실증 본선- 2027년 2월 시상식 [참가 신청 방법]대회 공식 홈페이지 신청🔽https://agrichallenge.ai/🔽1️⃣ 참가팀 및 팀장 정보 입력 후 제출2️⃣ 운영사무국에서 팀 정보 확인 후 팀별 ID와 PW를 발급3️⃣ 팀 정보는 마감기한(6월 29일)까지 변경 가능🍗신청 선착순 50팀에게는 치킨 기프티콘을 드립니다🎉 💡경진대회에 대해서 궁금한 것이 있다면?6월 15일 한국농업기술진흥원 유튜브 채널에서 진행되는2026 스마트농업 AI 경진대회 ‘설명회’를 참고하세요!15일 이후에도 영상이 남아있으니 언제든 보실 수 있습니다! 🚨잠깐! 팀원을 찾고 계신가요?디스코드에서 경진대회에 함께 참가할개발자, 데이터분석가, 농업 종사자를 찾아 드림팀을 만들어 보세요!https://discord.gg/DfjcR6AN54
트렌들리
1

[현직자 무료 AI 교육] 동그라미재단 AI 아카데미 5기(~6/14)
안녕하세요!이번에 AI 관련 직종의 현직자들, AI 초보자분들 모두를 위해 오픈된 무료 AI 교육 프로그램을 소개합니다.전 교육 과정 무료로 진행되는 해당 프로그램은 프롬프트, 바이브 코딩 강의로 구성되어 있으며, 초보자부터 현직 AI 관련 직종 전문가들까지 수강 가능한 커리큘럼으로 구성되어 있습니다. 이전 기수까지는 서울에서 진행되었는데, 이번에 부산외국어대학교와 협력하여 부산에서 해당 프로그램이 오픈 되었는데요!이번주 일요일(6/14)까지 모집한다고 하니, 많은 관심과 참여 부탁드립니다 🔥⠀ 🤖동그라미재단 AI 아카데미 5기(부산) 모집🤖AI 시대, 나의 가능성과 경쟁력을 확장하고 싶다면?동그라미재단 AI 아카데미는 AI 실무 교육을 통해 개인의 취·창업 및 직무 역량 강화를 지원하는 무료 AI 교육 프로그램입니다✨⠀⠀📅 모집 기간~ 2026년 6월 14일(일) 💸 참가 비용전액 무료⠀ 👨🏫 교육 일정 및 과정-매주 토요일 14:00~18:00, 과정별 4회차 운영-교육일정: 6/20(토), 6/27(토), 7/4(토), 7/11(토) ① 프롬프트 기초: LLM 활용 극대화를 위한 프롬프트 엔지니어링② 프롬프트 심화: 에이전트를 위한 프롬프트 엔지니어링③ 바이브 코딩 기초: 바이브 코딩으로 만드는 나만의 서비스④ 바이브 코딩 심화: 클로드 코드 & 바이브 코딩 Deep Dive 🏢 교육장소부산외국어대학교 트리니티홀(부산 금정구 금샘로 485번길 65)※주말 무료 주차 가능 🎁 참여혜택-주최기관장 명의의 공식 수료증 발급-수료생 한정 비공개 AI 커뮤니티 초대 📌 자세한 참가 신청 및 상세 내용은하단 신청 링크 or 모집 포스터 QR을 통해 확인해 보세요!⠀https://thecircle.career.greetinghr.com/ko/circle-ai
동그라미재단
0

[현장 스케치]『이게되네 오픈클로』 출간 기념 오프라인 밋업 현장 속으로!
안녕하세요, 인공지능팩토리입니다! 🤖✨ 지난 5월 22일, 책으로 오픈클로(OpenClaw)에 입문한 귀여운(?) 초보 독자분들부터 이미 자신만의 짱짱한 AI 에이전트를 돌리고 계신 찐 실사용자분들까지 한자리에 모였습니다. 바로 『이게되네 오픈클로』 출간 기념 오프라인 밋업 현장인데요! 소규모로 모여 일방향 강의가 아닌, 서로의 삽질기를 나누고 '같이 만지작거리는' 인터랙티브한 분위기로 꽉 채워졌던 그 뜨거웠던 현장을 지금 공유합니다! 🚀 오프닝 키노트: 오픈클로의 현재와 다음 - 한준구밋업의 문은 『이게되네 오픈클로』의 저자이신 한준구 님의 키노트로 열렸습니다. 현재 오픈클로 프레임워크가 어디까지 발전했는지, 그리고 앞으로 마주할 '다음 단계'는 어떤 모습일지 저자가 직접 풀어내는 흥미진진한 로드맵을 들을 수 있었는데요. AI 에이전트 시장의 최신 트렌드와 활용 노하우가 쏟아져 참가자분들의 눈빛이 초롱초롱 빛나던 순간이었습니다. 라이브 데모 — 5분 만에 띄우는 텔레그램 에이전트백문이 불여일견! 현장에서 가장 환호성이 컸던 라이브 데모 세션이었습니다. 복잡한 코딩 없이, 슬라이드 화면을 따라가다 보니 단 5분 만에 스마트폰 리모컨 역할을 하는 텔레그램 AI 에이전트가 뚝딱 완성되는 신세계를 목격했습니다. "저자님 사인해 주세요!" 열기 가득했던 책 사인회쉬는 시간과 함께 진행된 책 사인회! 미리 책을 지참해 오신 독자분들이 길게 줄을 서 주셨습니다. 저자님은 한 분 한 분께 감사 인사를 건네며 정성스레 사인을 해주셨고, 독자분들은 평소 책을 읽으며 궁금했던 점들을 직접 질문하는 등 훈훈하고 밀착된 소통의 시간이 이어졌습니다. 참가자 라이트닝 토크4명의 참가자분이 자신만의 에이전트·봇 운영 사례를 아낌없이 공유해 주셨습니다. "나만 고생한 게 아니구나!" 하는 깊은 공감대와 함께, 서로가 겪은 시행착오 속에서 진짜 알짜배기 꿀팁들을 주고받는 찐 커뮤니티의 매력을 제대로 느낄 수 있는 시간이었습니다. (발표해 주신 네 분께 다시 한번 감사드립니다! 🙇♀️)윤지환 님 이수연 님 이세영 님 최연준 님 Q&A이어진 Q&A 세션에서는 AI 에이전트를 운영할 때 필연적으로 발생하는 '검증의 누수(AI가 완벽하게 걸러내지 못하는 사각지대)'를 어떻게 해결해야 하는가에 대한 아주 깊이 있는 문답이 오갔습니다. 현업에 계신 분들의 폭풍 공감을 자아낸 대목이었는데요.저자님과 전문가분들이 제시한 핵심 팁은 생각보다 훨씬 현실적이고 명확했습니다.초반에는 결국 '사람의 눈'이 필요하다: AI가 모든 것을 완벽히 판단할 수 없기에, 검증 초기 단계에서는 사람이 직접 개입하여 AI가 놓치는 부분을 보완하고 학습 방향을 잡아주는 과정이 필수적이라는 점을 짚어주셨습니다.명확한 '평가 기준(명세)' 깎기: AI의 성능을 올리기 위해서는 정밀하게 정의된 평가 기준을 먼저 세워두고, 그 기준을 만족할 때까지 반복해서 테스트를 돌려야 누수를 최소화하고 안정적인 궤도에 올릴 수 있다는 실전 가이드를 공유해 주셨습니다.단순히 기술의 완벽함을 과신하기보다, 인간과 AI가 어떻게 협업하고 시스템을 튜닝해 나가야 하는지 진짜 '찐 사용자의 내공'을 배울 수 있는 값진 시간이었습니다. 『이게되네 오픈클로』 출간 기념 오프라인 밋업 마치며 짧은 시간이었지만 오픈클로를 사랑하는 분들의 열정 덕분에 운영진도 큰 에너지를 얻고 가는 밋업이었습니다. 앞으로도 인공지능팩토리는 이론을 넘어 '실전에서 직접 만지작거리며 성장하는' 유익한 장을 계속해서 만들어 나가겠습니다. 참석해 주신 모든 분께 감사드리며, 다음 행사에도 많은 관심과 참여를 부탁드립니다. 향후 더 좋은 기회로 다시 만나길 바랍니다. 감사합니다. 📺 아쉽게 현장에 함께하지 못하셨다면? '온라인 다시보기' 안내!이번 밋업의 열기 가득했던 현장을 실시간으로 함께하지 못해 아쉬워하시는 분들을 위해, 온라인 밋업 다시보기를 준비했습니다!한준구 저자님의 핵심 키노트부터 눈을 뗄 수 없었던 5분 라이브 데모, 그리고 꿀팁 가득했던 참가자 라이트닝 토크까지 모두 영상으로 다시 만나보실 수 있습니다.👉 『이게되네 오픈클로』 밋업 다시보기
AIFactory_PR
1

[AI에듀테크센터] Microsoft Specialist와 함께하는 AI 워크샵
💬 연세대학교 AI혁신연구원 AI에듀테크센터 주최“Microsoft Specialist와 함께하는 AI 워크샵” 🔥 Microsoft 전문가에게 직접 배우는 AI 실전 워크샵!코딩 없이도, Microsoft 기술로 나만의 AI 에이전트를 직접 만들어볼 수 있는 기회 과제·프로젝트·커리어까지Microsoft AI 도구 기반으로 바로 적용 가능한 활용 전략을 경험해보세요단순 사용이 아니라, 직접 만들고 설계하는 실전 중심 워크샵입니다. 👉 No-code 기반 AI Agent 생성 및 활용👉 Microsoft Specialist 직강👉 AI를 실제 학업과 커리어에 연결하는 방법까지 🌟 참가비 무료 ! AI에 관심있다면 소속 무관 누구나 참여 가능 !🔗 신청 링크: https://forms.gle/hQ4Kg9Sf6ZCPBBe46 🎁 5월 28일까지 사전 신청 시추첨을 통해 Microsoft Surface Pro 증정 (역대급 혜택✨) 🗓️ 2026.05.29 (금) 13:00–17:15✨ 연세대학교 백주년기념관
블레델
0

[현장 스케치] "프롬프트를 넘어, 실행 환경 '하네스'를 설계하다"(발표 자료 첨부)
안녕하세요, 인공지능팩토리입니다! 지난 4월 22일, 이번 밋업에 뜨거운 관심을 갖고 자리를 가득 채워주신 150명의 참가자 여러분 덕분에 정말 가슴 벅찬 하루를 보냈습니다. 현장의 열기가 정말 대단했죠! 🔥이번 밋업은 단순한 대화형 AI를 넘어, 현실의 복잡한 비즈니스를 실제로 쳐내는 '진짜 에이전트 시스템'을 만들기 위해 우리가 무엇을 준비해야 하는지 치열하게 논의하고자 기획되었습니다. 프롬프트를 넘어 실행 환경 전체를 설계하는 '하네스 엔지니어링'의 생생한 현장 속으로 여러분을 초대합니다! 입장 및 네트워킹본격적인 밋업이 시작되기 전임에도 불구하고, 행사장 강의실은 이번 행사에 대한 높은 관심을 증명하듯 일찍부터 빈자리 없이 수많은 참가자분으로 가득 채워졌습니다.많은 분들이 행사 시작 전부터 미리 도착하여 자리를 잡고 대기해 주셨습니다. 강의실을 가득 채운 참가자분의 모습 속에서, 이번 26Q2 밋업에 대한 현장의 뜨거운 열기를 그대로 체감할 수 있었습니다. 오거나이저 인사말이날 인사말에서는 환영의 메시지와 더불어, 이번 밋업을 들으면서 어떻게 하면 실무에 적용할 수 있는 더 좋은 배움을 얻어갈 수 있는지에 대한 솔직한 팁이 공유되었습니다. 발표자는 본인이 처음 생각했던 하네스는 '고양이 하네스(가슴줄)'였다는 유쾌한 비유를 들며, 완벽한 정답을 제시하기보다 오늘 이 자리에 모인 여러분과 함께 하네스 엔지니어링에 대해 차근차근 배워가고 싶다는 뜻을 전하였습니다. 주최 측과 참가자가 같은 선상에서 함께 성장하고자 하는 진정성 있는 메시지가 전달된 시간이었습니다. 하네스 엔지니어링을 사용한 목표달성 Loop 기능연사 : 우성우[ 하네스 엔지니어링을 사용한 목표달성 Loop 기능 발표 자료 ]본 세션에서는 AI가 정해진 제약 조건(Harness) 안에서 스스로 가설-실행-평가를 반복하며 최적의 결과물을 만들어내는 작동 원리가 소개되었습니다. 단순한 코드 생성을 넘어, AI가 스스로 발전하는 루프를 안전하게 통제하고 실무에 활용하는 현실적인 방안들이 다뤄졌습니다. MS 에이전트 프레임워크로 Harness Engineering 쉽게 배우기연사 : 이재석[ MS 에이전트 프레임워크로 Harness Engineering 쉽게 배우기 발표 자료 ]본 세션에서는 대규모 기업 환경에서 쓸 수 있는 에이전트와 멀티 에이전트 시스템의 하네스 구조를 살펴보았습니다. 특히 마이스터고등학교 학생들을 대상으로 진행했던 실제 실습 예제 코드가 함께 소개되어, 어렵게 느껴질 수 있는 에이전트 실행 환경을 누구나 쉽게 이해하고 감을 잡을 수 있는 유익한 시간이었습니다. 하네스 : 메타 스킬을 활용한 실전 AI 팀 빌딩 가이드연사 : 조남호[ 하네스 : 메타 스킬을 활용한 실전 AI 팀 빌딩 가이드 발표 자료 ]본 세션에서는 최근 핫한 클로드 코드(Claude Code) 환경에서 동작하는 하네스를 활용해 더 똑똑한 기능(메타 스킬)을 만드는 방법이 소개되었습니다. 하네스를 단순히 AI를 통제하고 관리하는 장치로만 보는 것이 아니라, 잘 활용하면 혼자 해결하기 어려운 복잡한 과제들도 얼마든지 풀어낼 수 있음을 보여주었습니다. 특히 오픈소스 라이브러리(revfactory/harness)를 통해 누구나 손쉽게 하네스 엔지니어링을 시작해 볼 수 있는 실무적인 팁이 공유되었습니다. 우리 조직만의 Harness 개발기연사 : 윤성재[ 우리 조직만의 Harness 개발기 발표 자료 ]본 세션에서는 '브레인크루' 조직에서 실제로 하네스를 구축하기 위해 클로드 코드(Claude Code) 플러그인을 직접 개발했던 생생한 경험이 공유되었습니다. 최근 주목받는 하네스 엔지니어링의 기본 원리부터 시작해, 실무에서 늘 헷갈리는 룰(Rule), 훅(Hook), 메모리(Memory) 등의 개념을 어떻게 명확히 구분하고 활용해야 하는지 실질적인 차이점을 짚어주었습니다. 나아가 플러그인 개발을 통해 조직 전체의 생산성을 끌어올리기 위한 현실적인 고민들을 함께 나누는 유익한 시간이었습니다. 패널토의이번 밋업의 마지막을 장식한 패널 토의 세션에서는 연사들이 한자리에 모여 '하네스(Harness)의 본질'에 대해 다양한 관점의 대화를 나누었습니다.패널들은 하네스를 "AI 모델이 통제를 벗어나지 않고 원하는 결과물을 내도록 안전한 운동장(컨텍스트)을 만들어주는 종합 기술 세트"로 정의하며, 기술과 모델이 계속 바뀌더라도 중심을 잡고 범위를 통제할 수 있는 아키텍처 설계가 핵심이라는 점에 뜻을 모았습니다. 이와 함께 세션 말미에는 "앞으로도 계속 개발자를 할 것인가"라는 현실적인 질문을 포함하여, 에이전트 시대에 실무자들이 마주한 다양한 고민들을 주고받으며 자유로운 분위기 속에 토의가 마무리되었습니다. Harness Engineering Korea 26Q2 Meetup을 마치며바쁜 일과 시간 중임에도 불구하고 귀한 시간을 내어 자리를 가득 채워주신 참가자 여러분, 그리고 현업의 소중한 노하우를 아낌없이 나눠주신 연사분들 덕분에 모두가 많은 배움을 얻어 갈 수 있었던 뜻깊은 자리였습니다. 참여해 주신 모든 분께 진심으로 감사드리며 정말 수고 많으셨습니다.이번 밋업에서 나눈 하네스 엔지니어링의 인사이트들이 여러분의 실무와 프로젝트에 실질적인 도움이 되었기를 바랍니다. 인공지능팩토리는 앞으로도 지식과 경험을 나누는 유익한 행사로 다시 찾아뵐 테니, 다음 행사에도 많은 관심과 참여를 부탁드립니다. 향후 더 좋은 기회로 다시 만나길 바랍니다. 감사합니다.
AIFactory_PR
0

생성형 AI로 공공 업무의 미래를 그리다! 'K-water AI 러닝톤' OT 현장 스케치
안녕하세요! 인공지능팩토리입니다.최근 공공기관에서도 생성형 AI를 활용한 디지털 전환 열기가 뜨거운데요.그 중심에서 인공지능팩토리가 한국수자원공사(K-water) 임직원분들과 함께 아주 특별한 여정을 시작했습니다. 바로 'K-water 맞춤형 학습형 해커톤(AI 러닝톤)'입니다! 지난 오리엔테이션(OT)에서는 비전공자를 포함한 30개 팀이 모여, 업무 자동화부터 보고서 작성까지 AI 실무자가 되기 위한 첫발을 내디뎠습니다. 그 뜨거웠던 OT 현장 소식을 전해드립니다. 🔥 1부 - 러닝(Learning): 무엇을 배우고 어떻게 성장할까?발표 : 김태영 1부에서는 이번 행사의 핵심인 '학습'에 집중했습니다. 단순한 기술 습득을 넘어 실질적인 '업무 해결 능력'을 기르는 커리큘럼이 소개되었습니다.맞춤형 커리큘럼 설명: 이번 러닝톤에서는 생성형 AI를 활용한 업무 자동화, 바이브코딩 기반의 프로토타입 개발, AI 활용 보고서 및 PPT 작성법을 깊이 있게 다룹니다.동영상 강의 오픈: 자기주도 학습을 위한 온라인 강의 오픈 일정이 공유되었습니다.사전 면담 멘토링: 이번 행사의 차별점은 바로 '팀당 20분'씩 진행되는 사전 면담입니다. 총 10시간에 걸쳐 멘토링이 진행될 예정입니다.2부 - 톤(Thon): 실전을 위한 만반의 준비발표 : 임지수 2부에서는 실제 결과물을 만들어낼 '해커톤' 플랫폼 활용법과 운영 전반에 대한 안내가 이어졌습니다.플랫폼 및 계정 관리: 인공지능팩토리가 제공하는 전용 플랫폼 사용법을 익히고, 원활한 실습을 위한 계정 세팅을 완료했습니다.멘토링 시스템 안내: 전체적인 멘토링 진행 일정 등을 소개하였습니다.자유로운 Q&A: 플랫폼 사용 중 궁금한 점이나 해커톤 진행 방식에 대한 질의응답 시간을 가졌습니다. 비전공자도 아이디어만 있다면 AI 개발자가 될 수 있는 시대! K-water 임직원분들이 보여주신 열정만큼 놀라운 결과물들이 탄생하길 기대합니다.인공지능팩토리는 앞으로 진행될 멘토링과 본 행사에서도 최선을 다해 지원하겠습니다.공공기관 AI 도입 및 맞춤형 교육 문의는 언제든 인공지능팩토리로 연락주세요. 📩 문의 :cs@aifactory.page
AIFactory_PR
0



[SeSAC✕노드크루] LLM Agent를 활용한 서비스 기획 및 제작 과정 교육생 모집
🎇 AI의 등장, 대체될 것인가 활용할 것인가? 🎇도구에게 대체되는 사람이 아닌, 도구를 사용하는 사람은, 더 좋은 도구의 등장을 반가워합니다.이제는 LLM이 대체할 수 있는 능력이 아닌, LLM을 활용할 수 있는 능력을 배워야 할 시간입니다! 과정 신청하기(클릭)🧚수료생들의 생생한 후기가 궁금하다면?👉 2기 후기 보러가기(클릭)👉 1기 후기 보러가기(클릭) ✒️ 강사 소개 ✒️유태영 강사- 삼성 청년 소프트웨어 아카데미(SSAFY) 1~7기 전임교수- SeSAC 서초캠퍼스 DX2기 LLM Agent를 활용한 서비스 기획 및 제작 과정 강사- SeSAC 서초캠퍼스 DX1기 AI 기반 데이터 분석가 양성과정 강사- 동아일보 KDT 생성형 AI를 활용한 콘텐츠 크리에이터 양성과정 강사- 데이터분석서비스 개발자 취업캠프 강사- 멋쟁이사자처럼 5~6기 전체 대학생 온라인 강의 담당 강사- 4차 산업혁명 선도인재 양성과정 강사 김선재 강사- 삼성 청년 소프트웨어 아카데미(SSAFY) 2~5기 전임교수- 코드잇 풀스택 부트캠프 2기, 4기, 7기, 10기, 14기 주강사- 4차 산업혁명 선도인재 양성과정 강사- 코드잇 프로덕트 디자인 웹 파트 주강사- LLM 기반 AI 서비스 풀스택 개발 실무 경험 보유 ✨ 이 강의를 통해서 ✨- 기초부터 다지는 탄탄한 프로그래밍 능력을 갖출 수 있어요.- 다양한 서비스들을 연결해서 파편화되어 있는 업무들을 한 번에 자동화하는 경험을 해볼 수 있어요.- 작은 규모의 GUI Agent부터 큰 규모의 Code Base Agent까지 모두 설계 및 제작해볼 수 있어요.- 비즈니스 문제에서 GPT(LLM)를 활용할 수 있어요.- 데이터 분석 뿐만 아니라 다양한 LLM을 활용하는 업무 자동화 Workflow를 설계, 개발할 수 있어요.- 3번의 프로젝트를 통해 배운 이론을 실무에 적용하고 포트폴리오 준비까지 할 수 있어요. 🎯 이런 분들에게 추천해요 🎯- LLM 관련된 산업/직군으로 취업하거나 기존 커리어에 LLM 활용 능력을 추가하고 싶은 취업 준비생- LLM을 활용하여 문제 해결능력을 기르고 실제 삶의 문제들을 해결하고 싶은 라이프 해커- 프로그래밍 능력을 키우고 가장 최신의 기술로 동작하는 SW를 제작해보고 싶은 진취적인 도전자 🎁 수강 혜택 🎁점심 식대 10,000원 지원도서 구매비 지원무제한 간식과 커피1:1 전담 잡코디 취업 상담 ✅ 수강 전 확인 사항 ✅교육 장소: 서울특별시 서초구 신반포로 지하 188 청년취업사관학교 서초캠퍼스(고속터미널역 3번/4번출구 개찰구 통과 후 도보 1분 이내)교육 기간: 2026. 06. 29 ~ 2026. 10. 12지원 기간: ~ 2026. 05. 31신청 대상: 만 15세 이상 서울 시민 또는 서울 거소자/서울 소재 대학(원)생 및 졸업생/서울 소재 기업 근무 경력자정원: 30명문의: http://pf.kakao.com/_BxhXgG 과정 신청하기(클릭)
nodecrew
0

2026 AI EXPO KOREA(국제인공지능대전)에서 인공지능팩토리를 만나보세요!
안녕하세요, 인공지능팩토리입니다!오늘부터 3일간, 서울 코엑스에서 ‘2026 국제인공지능대전(AI EXPO KOREA)’이 진행됩니다. 올해 저희 부스에서는 한층 더 똑똑해진 차세대 AI 에이전트 2종을 중심으로 여러분의 업무 고민을 시원하게 해결해 드립니다! 🌟 2026 핵심 라인업어시 Air (Assi Air): 웹 기반의 영리한 에이전틱 CS 솔루션어시 Loop (Assi Loop): 스스로 코딩하고 업무를 완수하는 에이전트 📍 부스 방문 안내연구원들과 직접 대화하며, 우리 회사에 꼭 필요한 AI 자동화가 무엇인지 상담받아 보세요.일시: 2026. 05. 06(수) ~ 05. 08(금)장소: 서울 코엑스(COEX) D24 부스"시키는 일을 알아서 직접 하는 AI, 어시웍스" 지금 바로 코엑스 D24 부스에서 에이전트의 실체를 확인하세요! 문의: cs@aifactory.page
AIFactory_PR
0

[서울AI플랫폼] AI 협업, 서울AI플랫폼에서 시작하세요!
안녕하세요, 서울AI플랫폼 담당자입니다.혹시 AI 프로젝트를 찾는 데 어려움 겪은 적, 있으신가요?또는 내 전문성을 살릴 수 있는 협업 기회를 찾고 계신가요?그 고민, 서울AI플랫폼에서 해결해보세요! [협업 기회, 서울AI플랫폼에서 찾아보세요!]서울AI플랫폼에는 현재 AI 전문가 약 1,000명, AI 기업 500개사가 회원으로 등록되어 있어,다양한 도메인의 AI 전문가·기업에게 직접 협업 제안을 하실 수 있습니다.AI 프로젝트·공모전·경진대회·위원 모집 등, 지금 바로 협업 제안을 해보세요! [협업 제안, 이렇게 하시면 됩니다.]*각 타이틀 클릭 시, 상세 페이지로 바로 이동할 수 있어요.👨🏫 전문가 협업 : 키워드 검색 > 프로필 조회 > '협업 제안하기' 버튼 클릭🏢 기업 협업 : 키워드 검색 > 프로필 조회 > '협업 제안하기' 버튼 클릭🤝 프로젝트 협업 : 메인 '프로젝트' 배너 클릭 > '등록하기' 버튼 클릭 > 내용 작성 및 등록 [궁금한 게 있어요! Mini Q&A]🔎서울AI플랫폼이 뭔가요? > 서울AI재단이 지자체 최초로 구축한 AI 전문 협업 플랫폼으로, 지난 4월 15일(수)에 공식 오픈했습니다.🔎어떤 회원들이 등록되어 있나요? > AI 전문가(교수·연구원·직장인 등), AI 기업(AI 분야 기술·솔루션·비즈니스 보유 등) 회원이 등록되어 있습니다. AI 전문가·기업 프로필은 도메인, 전문 분야, 소속 등으로 세분화되어 있으며, 키워드 검색으로도 탐색이 가능합니다.🔎AI 전문가로 활동하려면 어떻게 해야 하나요? > AI 관련 학과 재학/졸업, 또는 AI 분야 경력·활동·연구 2년 이상 보유 중 1가지 조건을 충족해야 하며, 프로필 작성 및 승인 처리 후 AI 전문가로 활동하실 수 있습니다.🔎AI 전문가·기업·협업 이외에, 다른 콘텐츠도 있나요? > 국내외 AI 관련 보도자료 수집·요약을 제공하는 AI 정책, 실무에 활용 가능한 AI 툴 정보를 제공하는 AI 도구 콘텐츠도 마련되어 있습니다. 서울AI플랫폼은 현업에 계신 AI 전문가 분들의 참여를 기다리고 있습니다.😊지금 바로, 서울AI플랫폼에서 협업을 시작하세요!
서울AI플랫폼
1

🤖 Open SWE — 내부 코딩 에이전트를 위한 오픈소스 프레임워크
배경: 빅테크들은 이미 쓰고 있었다https://blog.langchain.com/open-swe-an-open-source-framework-for-internal-coding-agents/ 블로그 내용을 번역 및 요약한 것입니다. 요즘 잘나가는 엔지니어링 팀들은 AI 코딩 에이전트를 내부에 직접 구축해서 쓰고 있어요.Stripe → MinionsRamp → InspectCoinbase → Cloudbot각자 독립적으로 만들었지만, 놀랍게도 비슷한 아키텍처 패턴으로 수렴했습니다. LangChain은 이 공통 패턴을 분석해서 누구나 쓸 수 있는 오픈소스 프레임워크로 만든 게 바로 Open SWE예요.Open SWE 아키텍처 7가지 핵심1. 🧠 에이전트 기반: Deep Agents + LangGraph기존 에이전트를 포크하거나 처음부터 만드는 대신, Deep Agents 프레임워크 위에 조합(compose) 하는 방식을 택했어요. Ramp가 OpenCode 위에 Inspect를 만든 것과 같은 접근법입니다.Deep Agents가 개선되면 자동으로 혜택을 받음포크 없이 조직별 커스터마이징 가능2. 🏖️ 샌드박스: 격리된 클라우드 환경각 작업은 독립된 클라우드 샌드박스에서 실행됩니다. 실수가 발생해도 프로덕션 시스템에 영향 없이 격리돼요.지원 샌드박스 프로바이더: Modal, Daytona, Runloop, LangSmith (직접 구현도 가능)3. 🛠️ 도구(Tool): 적게, 하지만 정밀하게Stripe는 약 500개의 도구를 보유하지만 "도구의 양보다 품질이 중요"하다고 밝혔어요. Open SWE도 약 15개의 핵심 도구만 큐레이션해서 제공합니다.도구역할execute샌드박스 내 셸 명령 실행fetch_url웹 페이지를 마크다운으로 가져오기http_requestAPI 호출commit_and_open_prGit 커밋 + GitHub PR 자동 오픈linear_commentLinear 티켓에 업데이트 포스팅slack_thread_replySlack 스레드 답장4. 📚 컨텍스트 엔지니어링: AGENTS.md레포 루트에 AGENTS.md 파일을 넣어두면, 에이전트가 작업 시작 전 자동으로 읽어서 시스템 프롬프트에 주입합니다. 팀의 코딩 컨벤션, 테스트 요구사항, 아키텍처 결정 사항 등을 담아두면 돼요.5. 🎭 오케스트레이션: 서브에이전트 + 미들웨어서브에이전트: 복잡한 작업을 task 도구로 자식 에이전트에게 위임. 각 서브에이전트는 독립된 컨텍스트를 가짐미들웨어: 결정론적 로직을 에이전트 루프에 주입check_message_queue_before_model: 작업 중 도착한 메시지를 다음 모델 호출 전에 주입open_pr_if_needed: 에이전트가 PR을 안 열면 자동으로 열어주는 안전망6. 🚀 호출 방식: Slack, Linear, GitHub개발자들이 이미 쓰는 도구에서 바로 호출할 수 있어요.Slack: 봇 멘션 → 스레드에서 상태 업데이트 + PR 링크 답장Linear: 이슈에 @openswe 댓글 → 👀 반응 후 결과를 댓글로 포스팅GitHub: 에이전트가 만든 PR에 @openswe 태그 → 리뷰 피드백 반영 후 같은 브랜치에 푸시7. ✅ 검증: 프롬프트 기반 + 안전망린터, 포매터, 테스트를 커밋 전에 실행하도록 지시하고, open_pr_if_needed 미들웨어가 최종 안전망 역할을 합니다.내부 구현체들과 비교항목Open SWEStripe (Minions)Ramp (Inspect)Coinbase (Cloudbot)기반Deep Agents/LangGraphGoose 포크OpenCode 조합처음부터 직접 개발샌드박스플러거블AWS EC2Modal자체 인프라도구 수~15개~500개OpenCode SDKMCPs + 커스텀호출 방식Slack, Linear, GitHubSlack + 버튼Slack + 웹 + 크롬 확장Slack 네이티브커스터마이징 포인트Open SWE는 완성품이 아닌 시작점입니다. 모든 주요 컴포넌트를 교체할 수 있어요.샌드박스 프로바이더 교체모델 변경 (기본값: Claude Opus 4)내부 API/배포 시스템용 도구 추가Slack/Linear/GitHub 트리거 수정미들웨어로 승인 게이트, 로깅, 안전 체크 추가마무리Open SWE는 "AI 코딩 에이전트를 우리 팀에 도입하고 싶은데 어디서부터 시작해야 할지 모르겠다"는 팀을 위한 프레임워크입니다. Stripe, Ramp, Coinbase가 수개월에 걸쳐 수렴한 아키텍처 패턴을 오픈소스로 공개한 것이기 때문에 시작하시는 분들에게 좋은 선택이 될 것 같습니다. MIT 라이선스이고, 기본 LLM은 Claude Opus 4 기반으로 동작합니다.🔗 GitHub: https://github.com/langchain-ai/open-swe📖 블로그: https://blog.langchain.com/open-swe-an-open-source-framework-for-internal-coding-agents/📚 Deep Agents 문서: https://docs.langchain.com/oss/python/deepagents
AF 김태영
2



[무료세미나] "LLM을 위한 퀀텀 어텐션 기법"와 같은 논문을 AI로 작성 및 리뷰해보기
이전 세미나에서는 클로드 스킬의 개념과 K-Dense-AI의 140여 개 과학 전용 스킬을 소개드렸습니다. 이번 무료 세미나에서는 실제로 스킬을 이용해서 AI로 논문을 함께 작성하고 리뷰까지 해보겠습니다. 아래 논문은 제가 세미나 준비를 위해서 사전에 테스트한 논문입니다. 40분 정도 소요되었습니다. 💡 세미나 핵심 내용Scientific Writing 워크플로우: 2단계 작성법IMRAD 구조: Introduction, Methods, Results, And DiscussionFigure 요구사항: 논문당 최소 5-6개 그림 생성 전략실험 코드 작성: AI와 협업하여 구현 가능한 코드 작성리뷰는 어떻게 할 것인가?📺 세미나 안내주제: "LLM을 위한 퀀텀 어텐션 기법"와 같은 논문을 AI로 작성 및 리뷰해보기일시: 1월 29일(목) 저녁 10시라이브 참여 : https://aifactory.space/task/9262/overview🧑🚀 연사 소개 I 김태영인공지능팩토리 CEOLangChain AmbassadorMicrosoft RD & AI MVP랭체인코리아 / 케라스코리아 / 캐글코리아 운영진블록과 함께하는 파이썬 딥러닝 케라스 저자(전) 한컴인스페이스 기술이사(전) 한국항공우주연구원 연구원💖 연계대회 참여하기본 세미나는 “2026 AI Co-Scientist Challenge Korea (AI 연구동료 경진대회) - 대상수상팀 최대 500만원 상금 지급” 연계 세미나로, 대회 참여자를 대상으로 진행됩니다.상단 태스크 제목을 클릭합니다. (아래 이미지에서 노란색 영역) 그 후 태스크 페이지에 있는 [참여하기] 버튼을 통해 신청해 주세요.혹은 https://aifactory.space/task/9235/overview 링크에서 [참여하기] 버튼을 클릭하세요.참여입력폼의 11번째 항목에 “세미나 신청 목적” 이라고 기입합니다.
AF 김태영
1


Claude Code Max Plan 2개이상 필수인 사람의 사용법
2026년 현재, 클로드는 개발자의 단순한 보조 도구를 넘어 실질적인 코딩 엔진으로 진화했습니다. 특히 복잡한 아키텍처를 설계하거나 방대한 코드베이스를 다루는 전문가들에게 클로드의 성능은 업무 효율의 핵심입니다. 하지만 생산성을 극한으로 끌어올리려는 파워 유저들에게는 늘 쿼터에 대한 갈증이 있기 마련입니다.이번 세미나에서는 “Claude On Steroids”라는 주제로, 클로드 코드를 한계까지 밀어붙여 사용하는 실전 노하우를 공유합니다. 특히 Claude Code Max 플랜을 2개 이상 운용해야만 하는 헤비 유저들을 위한 효율적인 워크플로우와 최적화 전략을 심도 있게 다룰 예정입니다. 💡 세미나 핵심 내용Oh-my-Claude: 이걸 만들면서 깨달은 건, AI가 멍청한 게 아니라 금방 잊어버린다는 것이었어요. 한 번에 잘 시키는 것보다, 다시 돌아와서 고치게 만드는 구조가 훨씬 중요했습니다. 그래서 이 프로젝트는 AI를 똑똑하게 가르치기보다, 계속 생각하게 만드는 틀을 만든 거예요. 📺 세미나 안내주제: Claude On Steroids일시: 1월 27일(화) 저녁 9시사전 신청: https://aifactory.space/task/9235/overview 🧑🚀 연사 소개 I 허예찬Quant.start()퀀트트레이딩과 Llm에 관심이 많습니다. 💖 세미나 참여하기본 세미나는 “2026 AI Co-Scientist Challenge Korea (AI 연구동료 경진대회) - 대상수상팀 최대 500만원 상금 지급” 연계 세미나로, 대회 참여자를 대상으로 진행됩니다.상단 태스크 제목을 클릭합니다. (아래 이미지에서 노란색 영역) 그 후 태스크 페이지에 있는 [참여하기] 버튼을 통해 신청해 주세요.혹은 https://aifactory.space/task/9235/overview 링크에서 [참여하기] 버튼을 클릭하세요.참여입력폼의 11번째 항목에 “세미나 신청 목적” 이라고 기입합니다.
AIFactory_PR
3
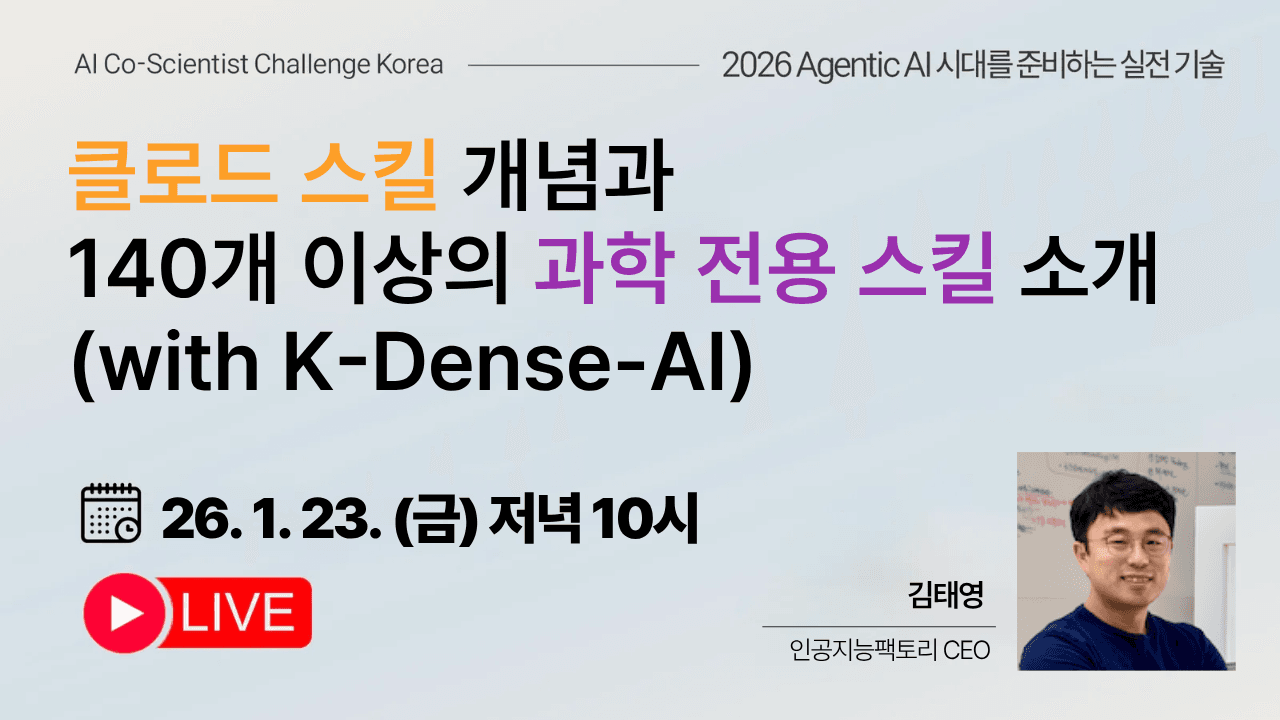
클로드 스킬 개념과 140개 이상의 과학 전용 스킬을 공개합니다.
2026년 인공지능은 단순히 질문에 답하는 수준을 넘어 스스로 도구를 사용하고 문제를 해결하는 에이전틱 AI 시대로 완전히 접어들었습니다. 이제 우리는 AI가 어떤 기술을 갖추고 복잡한 연구를 수행하게 할 것인지가 중요한 시점에 와 있습니다.이번 세미나에서는 최근 주목받는 클로드 스킬의 개념을 정리하고, 특히 K-Dense-AI의 140여 개 과학 전용 스킬을 집중적으로 소개해 드리고자 합니다. 💡 세미나 핵심 내용클로드 스킬이란 무엇인가요? 클로드 스킬은 AI 모델이 외부 API나 도구를 직접 호출하여 실행할 수 있는 능력을 의미합니다. 단순히 텍스트를 생성하는 것이 아니라, 데이터를 분석하고 실험 장비를 제어하거나 복잡한 계산을 스스로 수행할 수 있게 만드는 에이전트의 '손과 발'이 됩니다.K-Dense-AI가 공개한 140+ 과학 전용 스킬 과학 연구는 전문적인 도구와 정밀한 데이터 처리가 필수적입니다. K-Dense-AI에서 개발한 140개 이상의 과학 특화 스킬들을 살펴봅니다. 물리, 화학, 바이오 등 다양한 도메인에서 AI가 어떻게 전문가급 연구 보조 수행이 가능한지 확인하실 수 있습니다.멀티스텝 작업의 자동화와 재현성 단일 작업이 아닌, 여러 스킬을 유기적으로 조합하여 하나의 연구 프로세스를 완성하는 과정을 다룹니다. 특히 연구에서 가장 중요한 '재현 가능성'을 확보하면서도 업무 효율을 극대화하는 실전 노하우를 공유합니다. 📺 세미나 안내주제: 클로드 스킬 개념과 140개 이상의 과학 전용 스킬 소개 (with K-Dense-AI)일시: 1월 23일(금) 저녁 10시사전 신청: https://aifactory.space/task/9235/overview 🧑🚀 연사 소개 I 김태영인공지능팩토리 CEOMicrosoft RD & AI MVP랭체인코리아 / 케라스코리아 / 캐글코리아 운영진블록과 함께하는 파이썬 딥러닝 케라스 저자(전) 한컴인스페이스 기술이사(전) 한국항공우주연구원 연구원 💖 세미나 참여하기본 세미나는 “2026 AI Co-Scientist Challenge Korea (AI 연구동료 경진대회) - 대상수상팀 최대 500만원 상금 지급” 연계 세미나로, 대회 참여자를 대상으로 진행됩니다.상단 태스크 제목을 클릭합니다. (아래 이미지에서 노란색 영역) 그 후 태스크 페이지에 있는 [참여하기] 버튼을 통해 신청해 주세요.혹은 https://aifactory.space/task/9235/overview 링크에서 [참여하기] 버튼을 클릭하세요.참여입력폼의 11번째 항목에 “세미나 신청 목적” 이라고 기입합니다.
AIFactory_PR
3